Ansible 技巧与诀窍:处理不可靠的连接和服务
Ansible 技巧与诀窍:处理不可靠的连接和服务
Red Hat Ansible 自动化以自动化和配置 Linux 和 Windows 主机以及网络自动化(包括路由器、交换机、防火墙和负载均衡器)而闻名。此外,还有一些模块用于处理云和云 API,例如 Microsoft Azure、Amazon Web Services (AWS) 和 Google Compute Engine。还有其他模块可以与软件即服务 (SaaS) 工具(如 Slack 或 ServiceNow)交互。虽然这些 API 的停机时间非常少,但确实会发生,更常见的情况是,您的 Ansible 控制主机(您运行 Ansible 的地方)与以云为中心的 API 之间的连接可能会断开。
在这篇博文中,我将介绍一些处理与以云为中心的 API 的不可靠连接的技巧,以及我如何以可靠的方式构建 Ansible 剧本。作为一名技术营销工程师,我认为我的客户是 Red Hat 驻场团队,并且解决方案架构师经常在不可靠的酒店无线网络、咖啡馆甚至飞机上运行剧本!我必须确保剧本在这些特殊情况下具有一定的鲁棒性。当您的无线网络断开几秒钟,导致一个 20 个任务的剧本在第 19 个任务处失败时,这真是令人抓狂。如果您正在机场试图设置演示或游乐场以向客户展示某些东西,那么这种情况尤其令人沮丧。
Until 循环
许多使用 Ansible 的人都非常熟悉循环结构。循环(以前称为 with_items)非常简单且强大,允许您以简单的方式迭代列表或字典。但是,我发现许多人没有意识到 until 循环。让我们看看它如何工作。
模块 ec2_vpc_net 允许我们创建 AWS 虚拟私有云。
- name: Create AWS VPC sean-vpc ec2_vpc_net: name: "sean-vpc” cidr_block: "192.168.1.0/16” region: "us-east-1” register: create_vpc until: create_vpc is not failed retries: 5
name、cidr_block 和 region 是 ec2_vpc_net 模块的模块参数。但是 register、until 和 retries 是任务级参数,这意味着您可以在任何模块上使用它们。此任务将尝试创建 VPC 五次,然后放弃并失败。
让我们后退一步,看看它是如何工作的。每次运行任务时,任务都会返回一些通用变量,以让我们知道任务执行情况。
- name: test local playbook hosts: localhost gather_facts: false tasks: - name: dumb easy command shell: ls -la register: task_variable - name: debug the var debug: var: task_variable
当我们使用 ansible-playbook test_output.yml 运行此剧本时,我们会得到一些标准输出(通过 debug 模块),这些输出会打印到终端窗口(或使用 Ansible Tower 时打印到浏览器窗口)。
TASK [debug the var] ************************************************************** ok: [localhost] => task_variable: changed: true cmd: ls -la delta: '0:00:00.011018' end: '2018-12-07 09:53:14.595811' failed: false ...
我们从任何 Ansible 任务返回的关键值对之一是 **failed** 键。如果任务成功完成,任务将返回 failed: false。如果任务失败,任务将返回 failed: true。回顾一下 AWS VPC 任务的 until 循环逻辑
register: create_vpc until: create_vpc is not failed retries: 5
我们将任务的结果注册起来,这样我们就可以查看 failed 键值对。until 值是我们正在应用的条件。在这种情况下,我们不断运行任务,直到 create_vpc 不再具有 failed: true。但是,我们不希望任务无限期地运行。“retries” 的默认值为 3,但我将其增加到 5。until 循环为任务提供了显著的鲁棒性。还有一个可以与 until 循环结合使用的 delay 参数。delay 指的是两次重试之间等待的时间。delay 的默认值为 5 秒。查看 文档,以获取有关 until 循环和 delay 参数的更多详细信息和示例。
更改失败的含义
默认情况下,如果 Ansible 失败,剧本将在该任务结束,对于它正在运行的相应主机而言。如果我的剧本在 10 个主机上运行,并且它在 10 个任务中的第 3 个任务处在一个主机上失败,那么该主机将不会运行接下来的 7 个任务。其他主机将不受影响。
对于与外部 API 的不可靠连接,我们需要考虑哪些是必须的,哪些是定义剧本完成成功的非必须内容。例如,如果您有一个任务在 AWS 的 Route53 服务上启动 DNS 记录,那么 DNS 很好,但对于您开始使用创建的实例而言并非必需。我可以使用 until 循环使 route53 任务更可靠,但如果 Route53 服务不可用,则可能没问题。我可以使用 IP 地址在实例上完成一些工作,直到我获得更可靠的互联网连接来重新运行剧本或 Route53 服务再次可用为止。有些任务是“很好”,而有些是必须的。
忽略失败值的方法是使用 **ignore_errors** 参数,这是一个任务级参数,在 此处文档 中有介绍。我认为文档和各种博客中关于使用 ignore_errors 的内容已经很多,因此我认为了解 ignore_errors 将显示红色并报告一个 failed: true 键值对,但剧本将继续运行,就足够了。
如果我们想将 until 循环与 ignore_errors 结合使用,会发生什么?
- name: failure test playbook hosts: localhost gather_facts: false tasks: - name: purposely fail shell: /bin/false register: task_register_var until: task_register_var is not failed retries: 5 ignore_errors: yes - name: debug task_register_var debug: msg: "{{ task_register_var }}"
实际上,对于不可靠的任务,我们获得了这两个方面的优势。我们使用 until 循环获得了鲁棒性,并结合了 ignore_errors,这使剧本能够在该任务成功完成与否的情况下完成。我发现自己经常将 ignore_errors 和 until 循环结合使用,与 Let's Encrypt 等服务一起使用,因为对于我来说,拥有 SSL 证书来开始使用 Web 应用程序并非 100% 必须(我可以依靠自签名证书,直到我弄清楚问题为止)。
Ansible 剧本输出如下
TASK [purposely fail] ************************************************************* FAILED - RETRYING: purposely fail (5 retries left). FAILED - RETRYING: purposely fail (4 retries left). FAILED - RETRYING: purposely fail (3 retries left). FAILED - RETRYING: purposely fail (2 retries left). FAILED - RETRYING: purposely fail (1 retries left). fatal: [localhost]: FAILED! => changed=true attempts: 5 cmd: /bin/false delta: '0:00:00.007936' end: '2018-12-07 13:23:13.277624' msg: non-zero return code rc: 127 start: '2018-12-07 13:23:13.269688' stderr: '/bin/sh: /bin/false: No such file or directory' stderr_lines: - '/bin/sh: /bin/false: No such file or directory' stdout: '' stdout_lines: ...ignoring TASK [debug task_register_var] **************************************************** msg: attempts: 5 changed: true
在 Ansible 工作坊中,我实际上正在使用这种错误处理的组合,用于 Let's Encrypt,以使 Ansible 用户更容易排查问题。如果存在任何可以跳过的失败任务,我可以将其添加到变量中,并在工作坊剧本(负责为学生使用提供实例的剧本)结束时打印出来。
- name: failure test playbook hosts: localhost gather_facts: false vars: summary_information: | PROVISIONER SUMMARY ******************* tasks: - name: ISSUE CERT shell: certbot certonly --standalone -d student1.testworkshop.rhdemo.io --email ansible-network@redhat.com --noninteractive --agree-tos register: issue_cert until: issue_cert is not failed retries: 5 ignore_errors: yes - name: set facts for output set_fact: summary_information: | {{summary_information}} - The Lets Encrypt certbot failed, please check https://letsencrypt.status.io/ to make sure the service is running when: issue_cert is failed - name: print out summary information debug: msg: "{{summary_information}}"
这将在终端窗口中打印出一条非常容易理解的消息
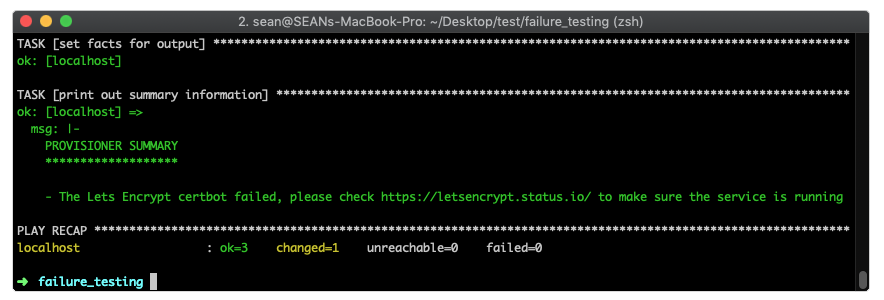
总之,Ansible 在必要时非常灵活地添加一些额外的逻辑。until 循环可以增强鲁棒性,而 ignore_errors 允许我们确定成功条件。结合起来,您的 Ansible 剧本将更加易于使用,使您能够对故障排除问题采取主动的方式,而不是被动的方式。Ansible 无法控制 API 或服务是否停机,但我们一定可以比自制脚本或 DIY API 实现运行得更可靠。提供的剧本极具可读性,新手用户也易于理解。