Ansible 和 Infoblox 角色深度解析
Ansible 和 Infoblox 角色深度解析
正如 Sean Cavanaugh 在他之前的 Infoblox 博客文章中提到的,Ansible 2.5 版本引入了查找插件、动态清单脚本和五个模块,这些模块允许进行 Infoblox 自动化。这些模块和查找在角色中的组合提供了一个强大的 DNS 自动化框架。
摘要
今天,我们将演示如何使用 Ansible 自动化 Infoblox Core 网络服务,帮助轻松、快速、可靠地管理网络中的 IP 地址和路由流量。您的虚拟化和云网络系统需要快速的供应生命周期;Infoblox 帮助您管理这些生命周期。与 Infoblox 配合使用时,Ansible 允许您自动化这些工作。Ansible 与 Infoblox 的集成灵活且强大:您可以使用模块或直接调用 Infoblox WAPI REST API 来自动化 Infoblox 任务。
这篇文章将引导您完成六个现实场景,在这些场景中,Ansible 和 Infoblox 可以简化您的网络任务
- 在一个位置创建一个提供程序,该提供程序可在角色集合中重复使用。
- 通过创建具有正向 DNS 区域的新子网来扩展您的网络。Infoblox 的 Ansible 模块使这个常见的两部分任务变得简单。
- 创建反向 DNS 区域,例如,标记来自任何没有关联地址名称的 IP 地址的电子邮件。对于旧版本的 Ansible,您必须使用对 Infoblox API 的调用来执行此任务,但从 Ansible v2.7 开始,
nios_zone模块现在支持此功能。 - 使用 Ansible 功能强大的 Jinja2 模板为新子网的网关地址保留主机记录。
- 使用循环和
host_count在子网中创建其他主机。 - 管理 Infoblox Grid 以大规模自动化您的网络,其中一个 Infoblox 设备可能不够。网格在物理上隔离您的受管网络并消除单点故障。
要按照您自己的 Infoblox 设备上的这些示例进行操作,您需要安装 dynamic-infoblox 角色 并将您的 Infoblox 凭据设置为提供程序。
Infoblox 凭据和 nios_provider
[任何时候您将 Ansible 与 Infoblox 结合使用时,调用 Infoblox 查找 或 模块 时,都必须指定 Infoblox IP、用户名和用户的密码。 我们的角色 将这些凭据统称为 nios_provider。通过将 nios_provider 字典创建为组变量,您可以在所有 playbook 和角色中一致地应用这些值,并在需要时使用一行代码引用它们。
*group_vars/all/main.yml* nios_provider: #Infoblox out-of-the-box defaults specified here host: 192.168.1.2 username: admin password: infoblox wapi_version: “v2.7”
使用模块设置子网和正向 DNS 区域
准备好凭据后,您可以运行一个 playbook,该 playbook 利用 dynamic Infoblox 角色创建子网和正向 DNS 区域;Ansible 模块可以轻松地完成此操作。创建子网是一个常见的网络项目:子网允许管理员扩展网络,以响应新的公司分支机构、办公室或业务线。正向 DNS 区域建立地址名称到 IP 地址的单向映射。企业可能需要一个新的 DNS 区域来扩展其全球覆盖范围到另一个国家/地区(例如 .uk)或响应合并。此处显示的任务将 ansible_subnet 和 ansible_zone 定义为变量,因此您可以在每次创建新子网时覆盖它们。
- name: Create a test network subnet nios_network: network: "{{ ansible_subnet }}" comment: Test network subnet to add host records to state: present provider: "{{ nios_provider }}" - name: "Create a forward DNS zone called {{ ansible_zone }}" nios_zone: name: "{{ ansible_zone }}" comment: local DNS zone state: present provider: "{{ nios_provider }}"
在此示例中,我们使用了默认的 Infoblox 视图。Infoblox 允许在单个 DNS 区域内使用多个视图。如果您想将内部流量路由到本地服务器并将外部流量路由到公共云服务器,您可以通过设计具有两个 DNS 视图的 DNS 区域来实现。这种类型的设置可确保到员工内联网的流量不会占用客户使用的服务器,从而提供更好的地理覆盖范围和更高水平的全天候客户覆盖范围。但是,对于上面的简单示例(以及后续示例),我们一直坚持使用默认视图。
使用 Infoblox API 设置反向 DNS 区域
到目前为止,您已经了解了如何使用 Ansible 模块来自动化 Infoblox 更改。我们的下一个示例展示了如何使用 Infoblox WAPI REST API 来自动化当前 Ansible 版本中可能不可用的任务。反向 DNS 区域允许客户端查找地址名称,前提是他们知道等效的 IP 地址。反向区域的重要性可以用一个常见的示例来说明:电子邮件服务器。来自没有关联地址名称的 IP 地址的传入流量通常会被标记为垃圾邮件。反向区域还可以帮助其他用例,例如收集有关访问您网站的其他企业的真实数据。
nios_zone 模块已经可以创建正向 DNS 区域,但它只能使用最新版本的 Ansible 创建反向区域。但是,您仍然可以在旧版本的 Ansible 中自动化此任务 - 只需使用 Ansible 直接对 WAPI API 进行调用即可。您可以使用 uri 模块或 shell 脚本来执行此操作。我们建议使用 uri 模块,因为它有助于更具描述性地捕获集成并支持利用标准 REST 返回代码的幂等调用。在此,uri 模块充当一个伞形模块,以简洁的方式捕获 Ansible 模块生态系统中的单个 WAPI 调用。值得注意的是,WAPI API 的工作方式与 Ansible 模块非常相似:输入 JSON 和输出 JSON。如果您以 yaml 表示 API 调用的主体,则可以轻松使用 Jinja2 过滤器(我们将在后面详细介绍)在运行时将其转换为 JSON。
- name: Create a reverse DNS zone to complement forward zone uri: url: https://{{ nios_provider.host }}/wapi/{{ wapi_version }}/zone_auth method: POST user: "{{ nios_provider.username }}" password: "{{ nios_provider.password }}" body: "{{ reverse_zone_yml | to_json }}" #201 signifies successful creation #400 signifies existing entry #both signify a successful WAPI call status_code: 201,400 headers: Content-Type: "application/json" validate_certs: no register: reverse_dns_create changed_when: reverse_dns_create.status == 201 vars: reverse_zone_yml: fqdn: "{{ ansible_subnet }}" zone_format: "IPV4"
如果您在创建任何主机记录之前建立子网、正向区域和反向区域,则您在该正向区域中创建的每个主机记录都会自动创建相应的反向区域条目!定义了网络、正向区域和反向区域后,就可以开始为新子网创建主机记录了。
使用 Jinja2 模板保留网关地址
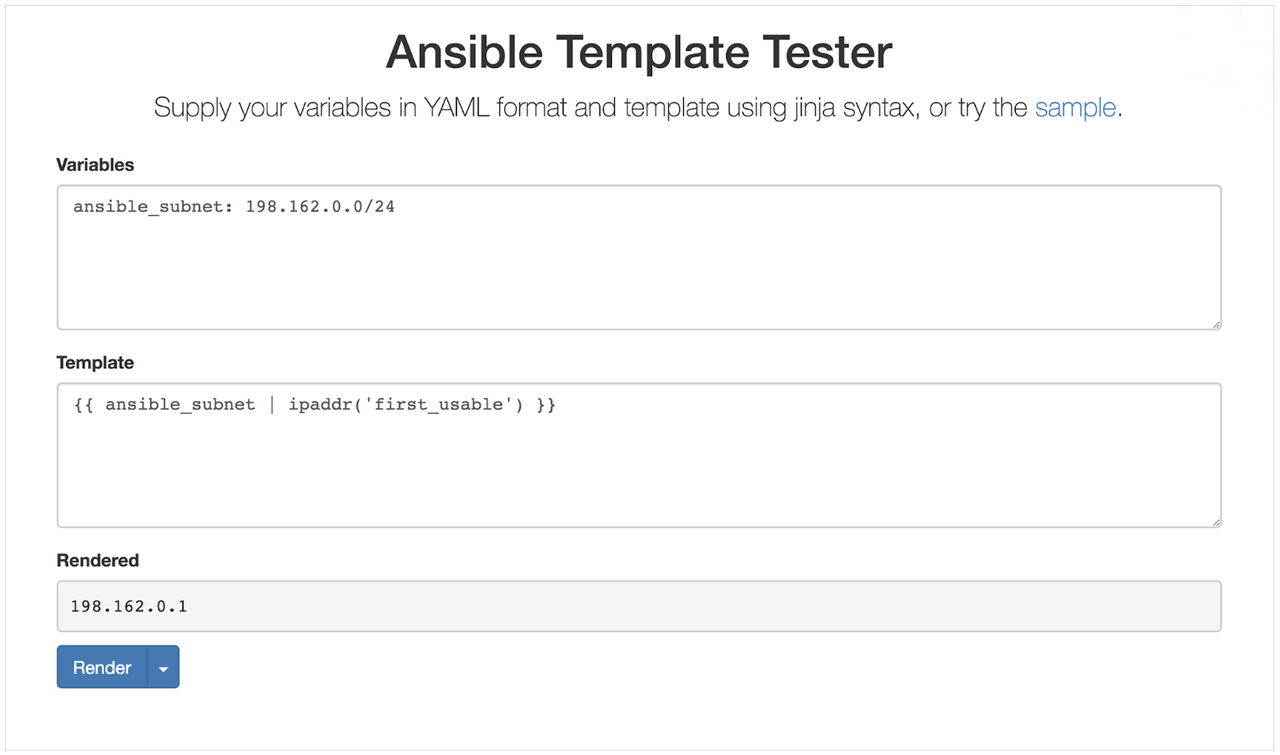
当您开始创建主机记录时,您希望将区域中的第一个(或最后一个)主机记录保留为网关地址,即转发目标 IP 地址位于直接网络外部的数据包的地址。如前所述,您可以使用 Jinja2 过滤器通过在其上调用简短的 python 函数来操作数据;Jinja2 过滤器的语法有效地充当 linux 管道。Jinja2 过滤器是一种快速操作数据的方法,在本例中,我们使用其中的两个(请参见下面的示例)来遵守 Infoblox 网关地址命名约定。需要注意的是,相对于子网定义网关地址名称可以避免网关地址名称被覆盖,因为每个子网通常都有自己的网关地址。
- name: Create a host record for the gateway address nios_host_record: name: “gateway{{ ansible_subnet | ipaddr(‘first_usable’) | replace(".","_") }}.{{ ansible_zone }}” ipv4: - address: "{{ gateway_address }}" state: present provider: "{{ nios_provider }}"
此任务使用此复杂的 Jinja2 表达式逐步构建网关主机名。Ansible 打包的 ipaddr 过滤器 非常通用 - 它能够完成大量的常规 IP 地址操作。例如,如果您的 IP 范围是 192.168.1.0/24 且您的 ansible_zone 是 ansible.local,则上面的任务中的过滤器将在一行中创建一个名称
- 表达式以“gateway”开头
- 中的部分执行以下操作:a. 检索 ansible_subnet 的模板化值
ansible_subnet => 198.168.1.0/24b. 使用检索到的 ansible_subnet 值并将其提供给 ipaddr('first_usable') 过滤器插件以获取第一个可用的 IP192.168.1.0/24 | ipaddr('first_usable') => 192.168.1.1c. 使用下划线而不是点来格式化结果 IP192.168.1.1 | replace('.', '_') => 192_168_1_1d. 在子网值之前添加.分隔符 e. 检索 ansible_zone 的模板化值ansible_zone => ansible.local
通过示例模板传递上面列出的值的网关主机名将是
gateway192_168_1_1.ansible.local
Jinja2 过滤器是一个复杂的 Ansible 主题;在构建您自己的 Jinja2 过滤器之前,您应该具备扎实的 Ansible 基础。当您开始创建过滤器时,您可以本地测试预期值,或者利用 Sivel 的 Ansible 模板测试器 在将过滤器用于 playbook 或角色之前查看其结果。
使用循环和 host_count 生成主机记录
一旦您的网关地址被预留,您可以使用循环生成已知数量的其他主机记录。在实际场景中,您可能会在子网内生成服务器组(例如,数据库服务器、应用程序服务器等)。对于此简单的演示,您可以定义一个循环,根据用户提供的host_count值动态生成通用主机记录。此演示展示了nios_next_ip查找插件的功能,该插件可以获取单个下一个可用 IP 或一系列下一个可用 IP 来分配。在一个包含这两个任务(上面创建网关地址主机记录的任务和下面生成主机记录的任务)的 Playbook 中,如果您没有定义host_count,则 Playbook 不会创建任何其他主机记录;只会创建网关地址。
#Generating records this way should be for demo purposes #Normal scenario would be to iterate over a dictionary/list of hosts or populate via a static csv file - name: “Dynamically generate {{ host_count }} host records at next available ip in {{ ansible_subnet }}” include_tasks: host_record_generation.yml loop_control: loop_var: count with_sequence: start=1 end={{ host_count }} when: host_count is defined
如果您基于用户提供的主机数量使用 Ansible 生成主机记录,那么循环遍历主机数量是否可能在第二次运行时导致索引问题?不幸的是,确实如此,但是保留生成的宿主机总数可以解决此问题。一种方法是在控制节点上维护一个静态的总主机计数文件,将其视为真相来源。通过利用 Ansible 的查找插件功能检索其内容,每次生成主机时,此文件中的计数都会递增,因此后续的角色执行(尤其是在不同子网中自动执行的角色)不会覆盖彼此的记录!
以这种方式生成主机记录与大多数企业使用的命名约定生成主机记录不同,但它是一种使用nios_next_ip查找插件开箱即用的简单方法,可以在不同的区域和/或子网中创建一些记录。Infoblox 还支持用于静态记录的 csv 记录导入功能。
使用 Ansible 预定义 Infoblox 网格
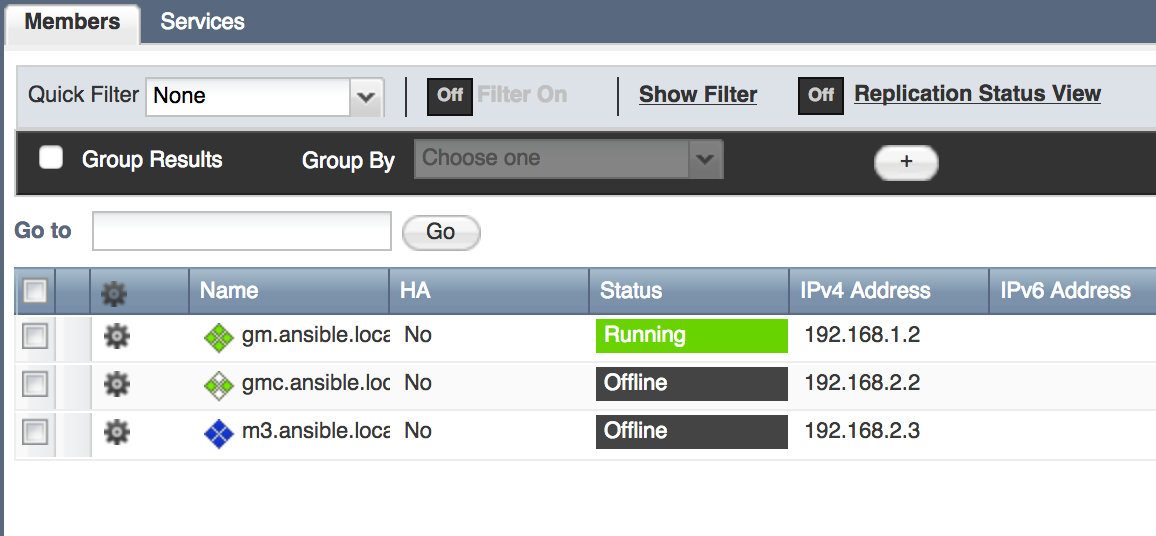
在前四个场景中,您已经了解了 Ansible 如何在主机和子网级别与 Infoblox 协同工作。Ansible 可以大规模地对 Infoblox 做些什么?自动化单个 Infoblox 实例可以提供价值,但生产 Infoblox 系统通常设计为网格形式。Infoblox 网站解释了 Infoblox 网格技术的全部功能。Infoblox 网格在单个或配对设备之间建立分布式关系,以消除传统 DNS、DHCP 和 IP 地址管理基础设施中固有的单点故障和其他运营风险。每个网格包含一个网格主节点和数量不等的其他网格成员和/或网格主节点候选者。网格成员仅包含完成其工作所需的部分 Infoblox 数据库。另一方面,网格主节点候选者拥有网格主节点数据库的实时完整副本,以提供灾难恢复功能。您可以使用我们的 Ansible 角色以这种方式预定义新的网格主节点候选者和网格成员
- name: Predefine a new Grid Master Candidate hosts: localhost connection: local roles: - role: predefineGridmasterCandidate master_candidate_name: gmc.ansible.local master_candidate_address: 192.168.2.2 master_candidate_gateway: 192.168.2.254 master_candidate_subnet_mask: 255.255.255.0 - name: Predefine a new Grid Member hosts: localhost connection: local roles: - role: predefineGridMember member_name: m3.ansible.local member_address: 192.168.2.3 member_gateway: 192.168.2.254 member_subnet_mask: 255.255.255.0
如您从这五个示例中看到的,Ansible 和 Infoblox 协同工作以快速、轻松、可靠地管理您的网络基础设施及其承载的流量。Ansible 基于 Infoblox WAPI API 的强大功能构建。使用 Ansible 模块和对 WAPI API 的直接调用,您可以编写可重用的 Ansible 角色和 Playbook,这些角色和 Playbook 可以快速适应处理不同的网络。如果您愿意,您可以从自定义ansible-networking 存储库中的角色开始,该存储库连接了今天文章中讨论的所有 Ansible 概念。