使用过滤器进行 Ansible 数据操作
今年的峰会上,一位与会者提出了一个关于如何在 Ansible 中使用设置事实和更改数据的问题。很多时候,我们遇到过使用一个接一个的任务来操作数据的人,将项目转换为列表,过滤选项,尝试进行大量数据操作,并将数据从一个来源转换为另一个来源。尝试使用角色和剧本中的 YAML 和 Jinja 混合来进行这些编程更改本身就是一件头疼的事情。虽然这些选项中的许多都可行,但它们效率不高,也不易于实施。Ansible 剧本从未打算用于编程。
通常被忽视的一种解决方案是在模块或过滤器内部使用 Python 进行操作。本文将详细介绍如何创建过滤器来操作数据。此外,本文中引用的所有代码的存储库已经创建。
此示例最初是作为模块开发的。但是,经过审查,我们确定这些数据转换最好作为过滤器进行。过滤器可以接收多个数据输入,执行编程操作,然后可以在作为输入使用的地方内联使用或设置为事实。此外,这在本地运行,而不是在主机级别运行,因此它可以更快,避免不必要的连接。
起点
首先,我们需要一个数据集来进行处理。为此,我们使用了来自自动化控制器 API 的数据,即工作流;它提供了关于每个工作流中的节点的嵌套数据以进行循环。在这种情况下使用的变量文件可以在仓库中找到。
目标是找出自动化控制器循环遍历嵌套列表时正在使用什么。虽然这不是一个非常实用的例子,但它确实为创建过滤器来操作任何数据集提供了一个起点。
过滤器基础知识
此过滤器的骨架取自ansible.netcommon.pop_ace。每个过滤器的开头都有一些必需的选项,例如 FilterModule,此外,AnsibleFilterError 有助于进行故障排除。
from ansible.errors import AnsibleFilterError
类调用将代码设置为过滤器,并调用用于过滤器的函数。这设置了在剧本中称为“used”的过滤器,以及要调用的函数。请注意,函数和过滤器名称不需要匹配。
class FilterModule(object): def filters(self): return {"example_filter": self.workflow_manip}
然后是文档部分:这可以包含输入、示例和其他元数据。这也是 ansible-docs 的填充方式。
EXAMPLES = r""" - name: Transform Data ansible.builtin.set_fact: data_out: "{{ workflow_job_templates | example_filter }}" """
在大多数情况下,这应该是标准信息。虽然文档字段对于过滤器不是必需的,但最好将其包含在内。虽然此处未显示,但链接的示例还包含已注释的预期输出,这对于将来回溯和进行故障排除非常有用。
设置
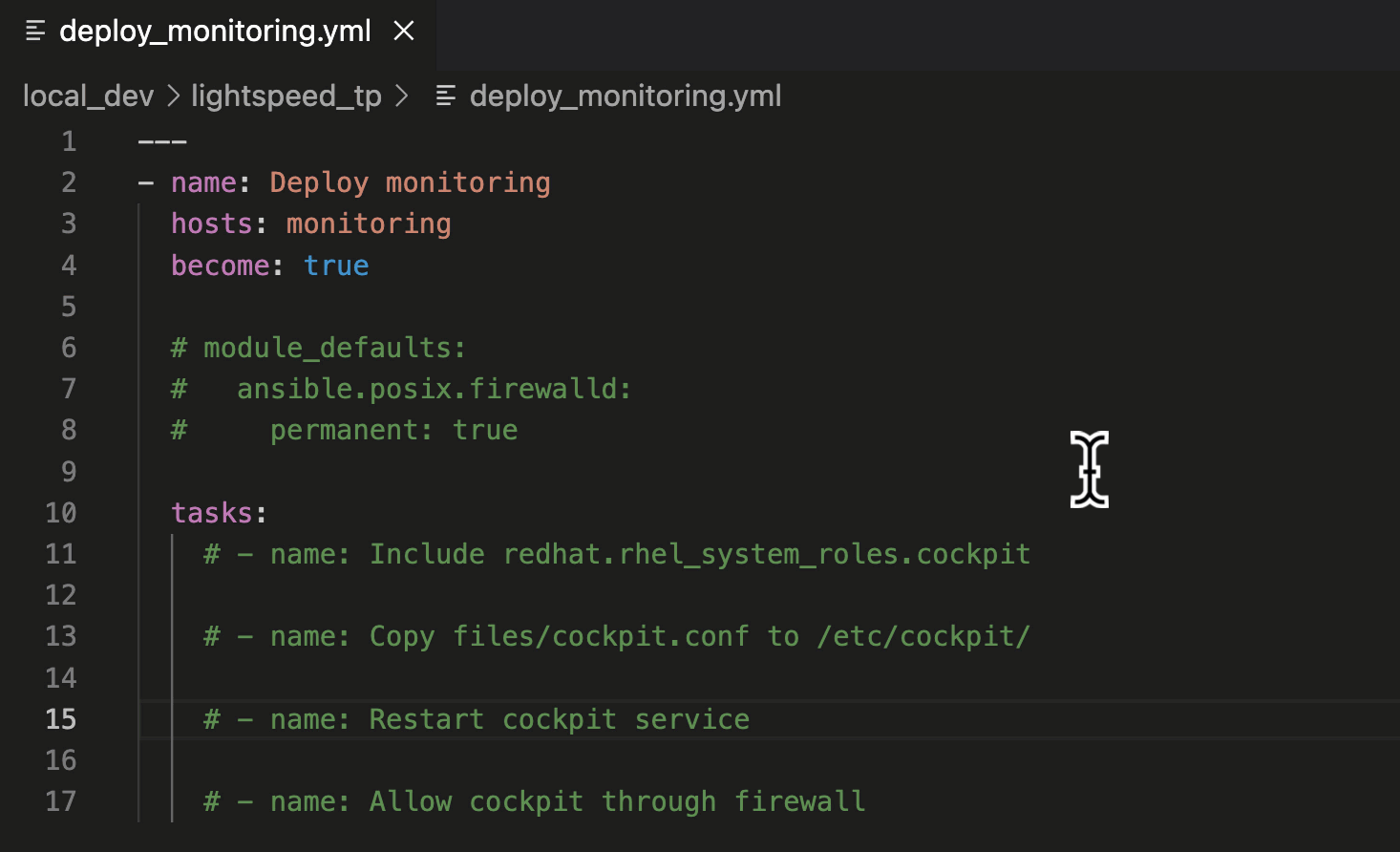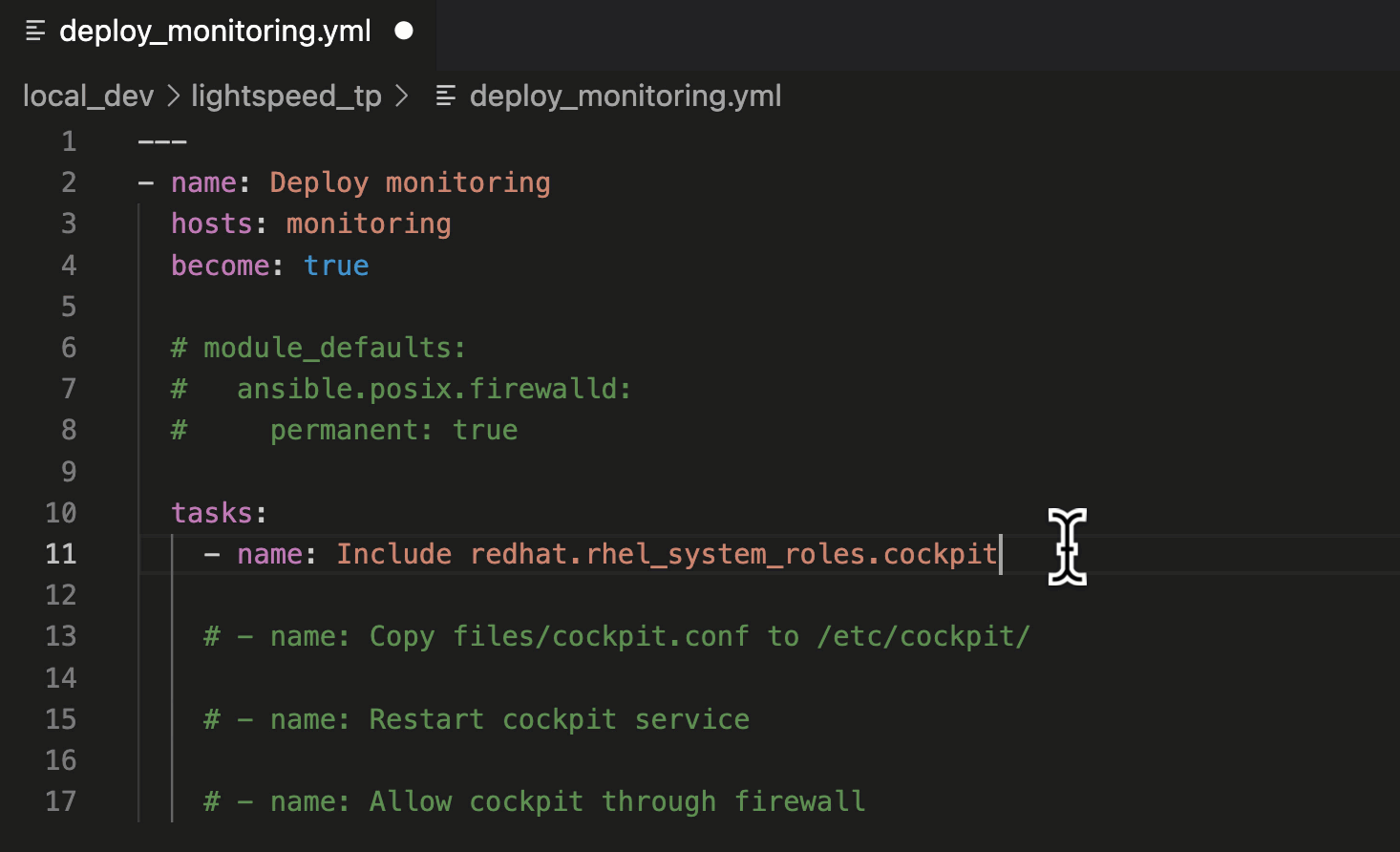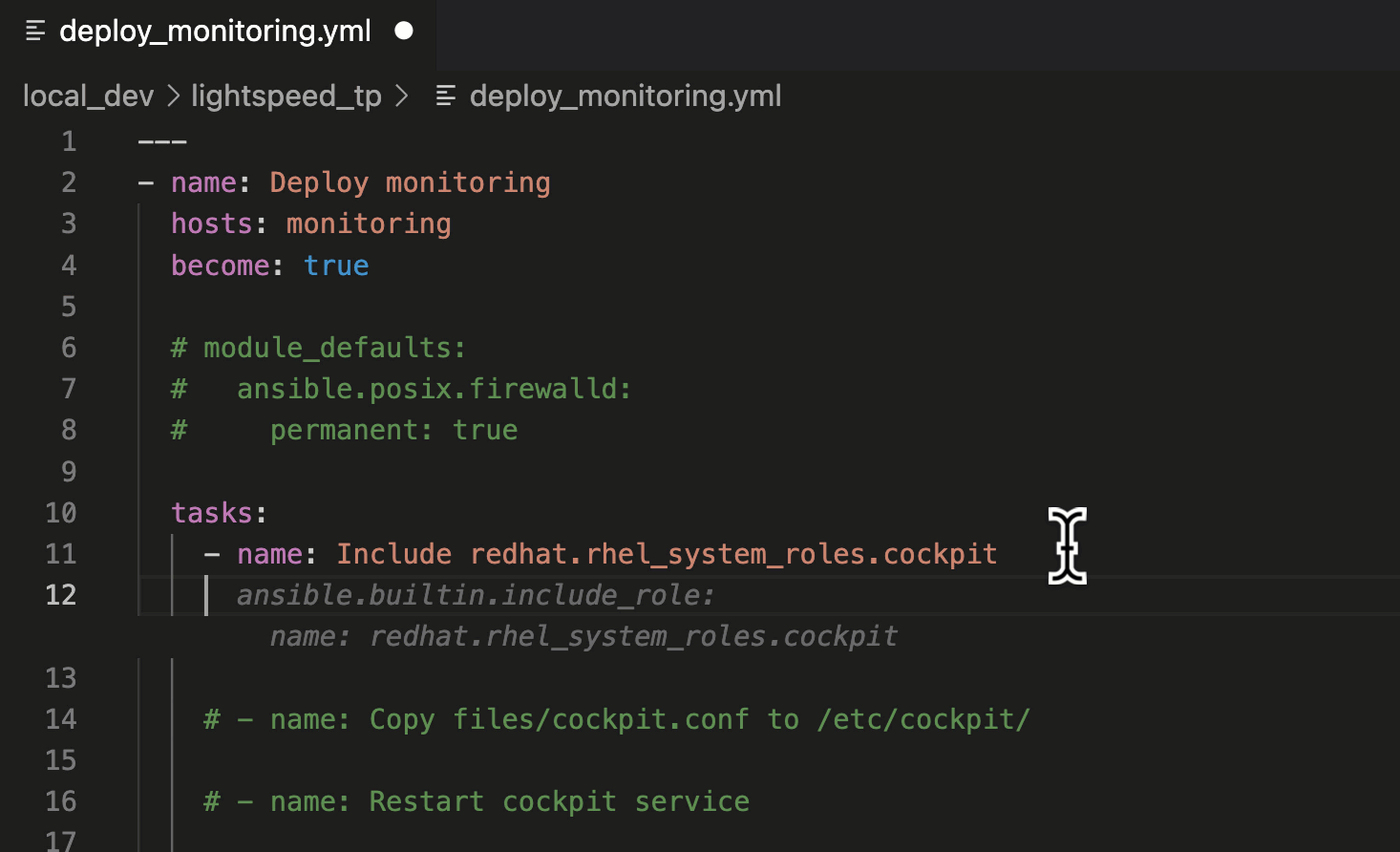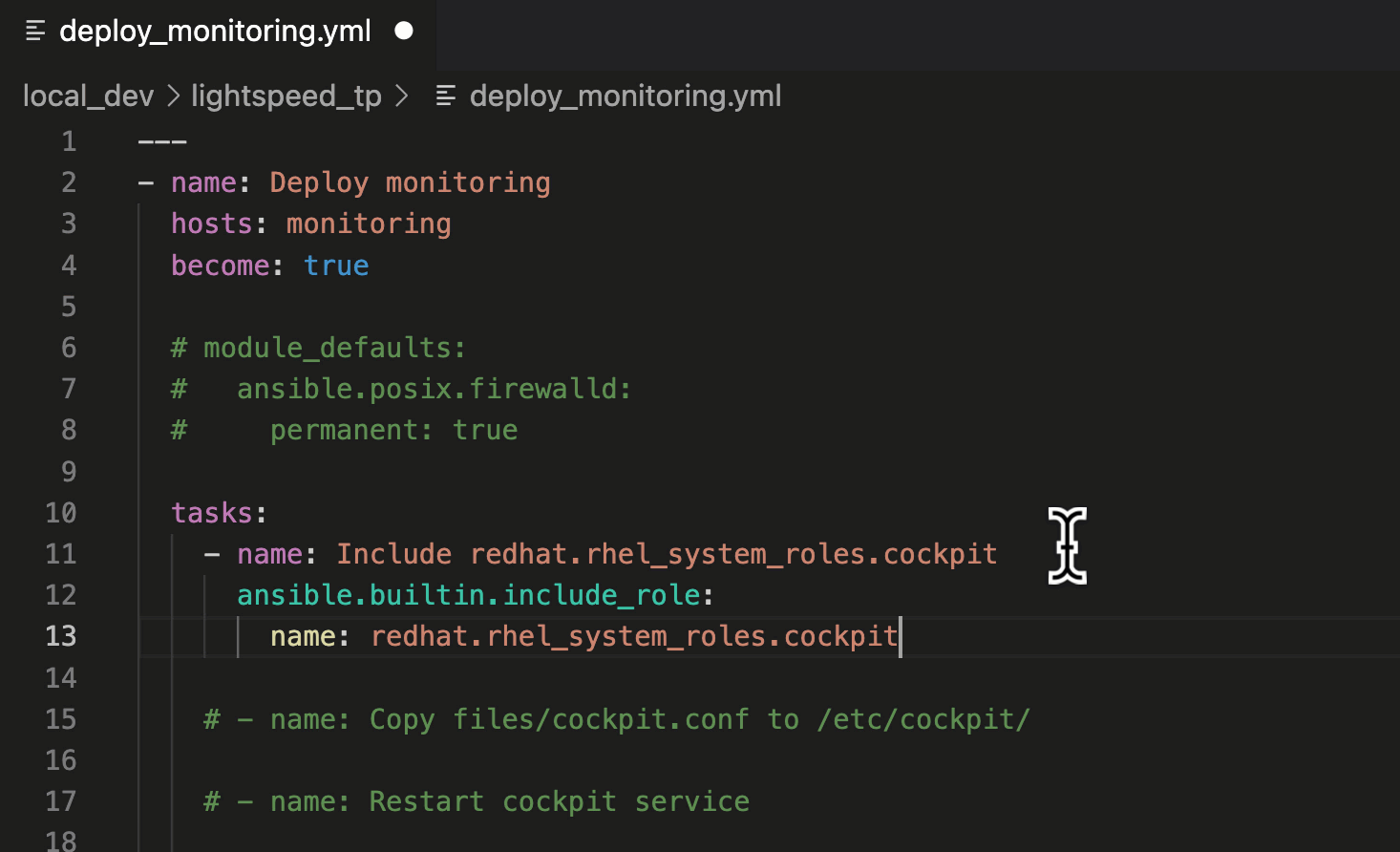
第一步是设置传入数据的过滤器参数。在我们的例子中,变量 data_in,以及输入的类型为字典。最好在此处将返回值设置为为空,以及需要定义的其他默认值。
def example_filter(self, data_in: dict): workflow_data = {} workflow_data["workflows"] = [] workflow_data["job_templates"] = [] workflow_data["inventory_sources"] = [] workflow_data["approval_nodes"] = []
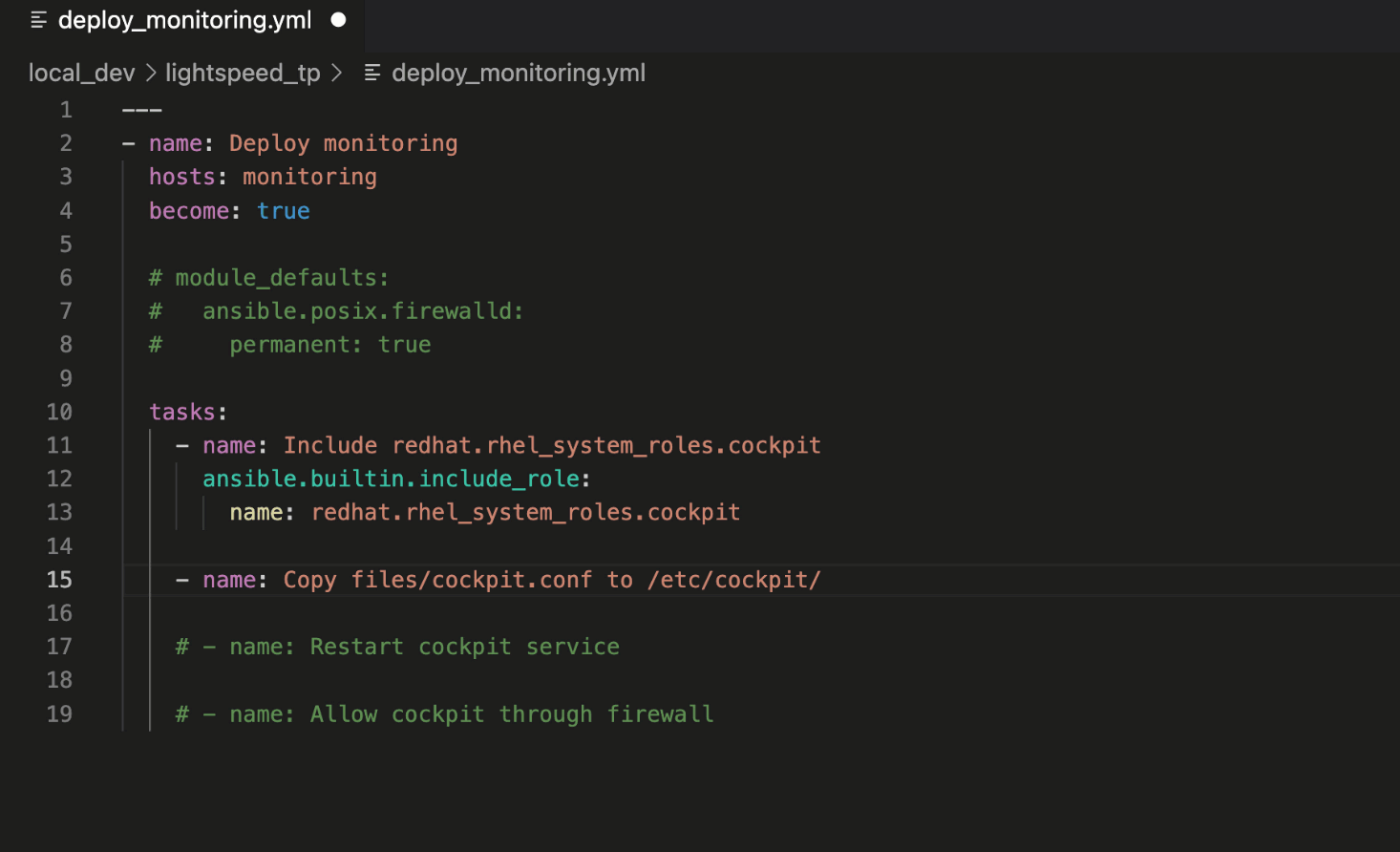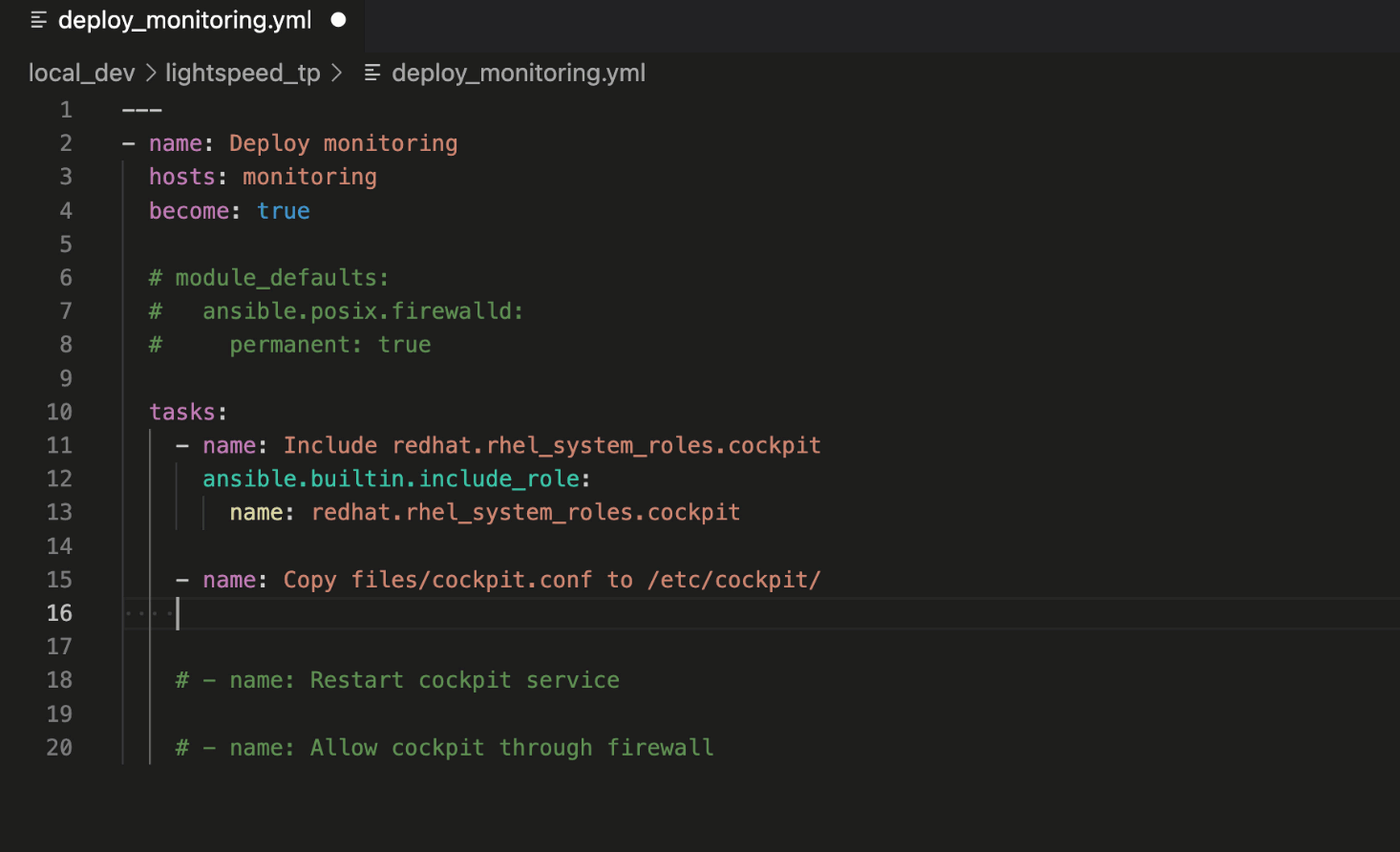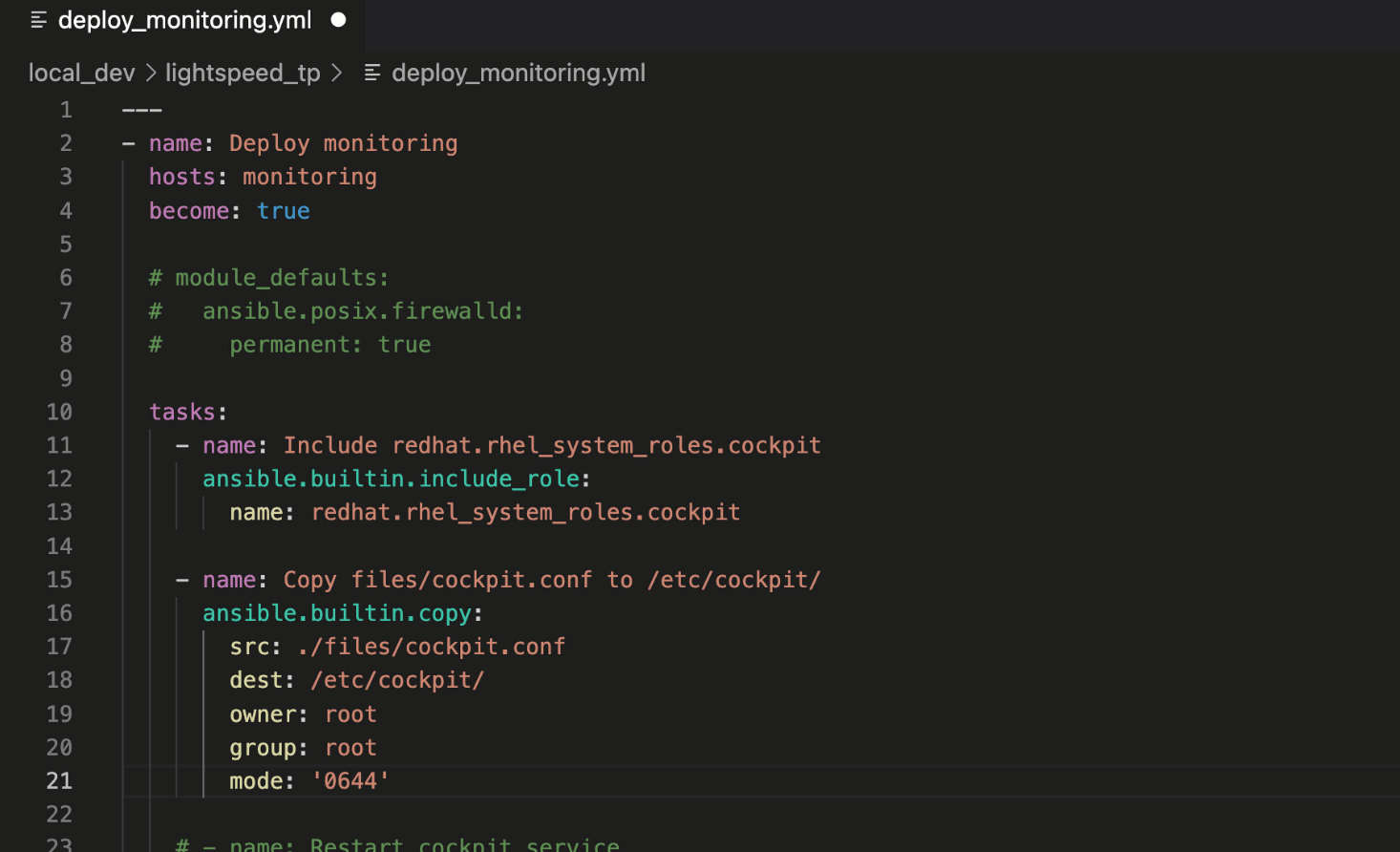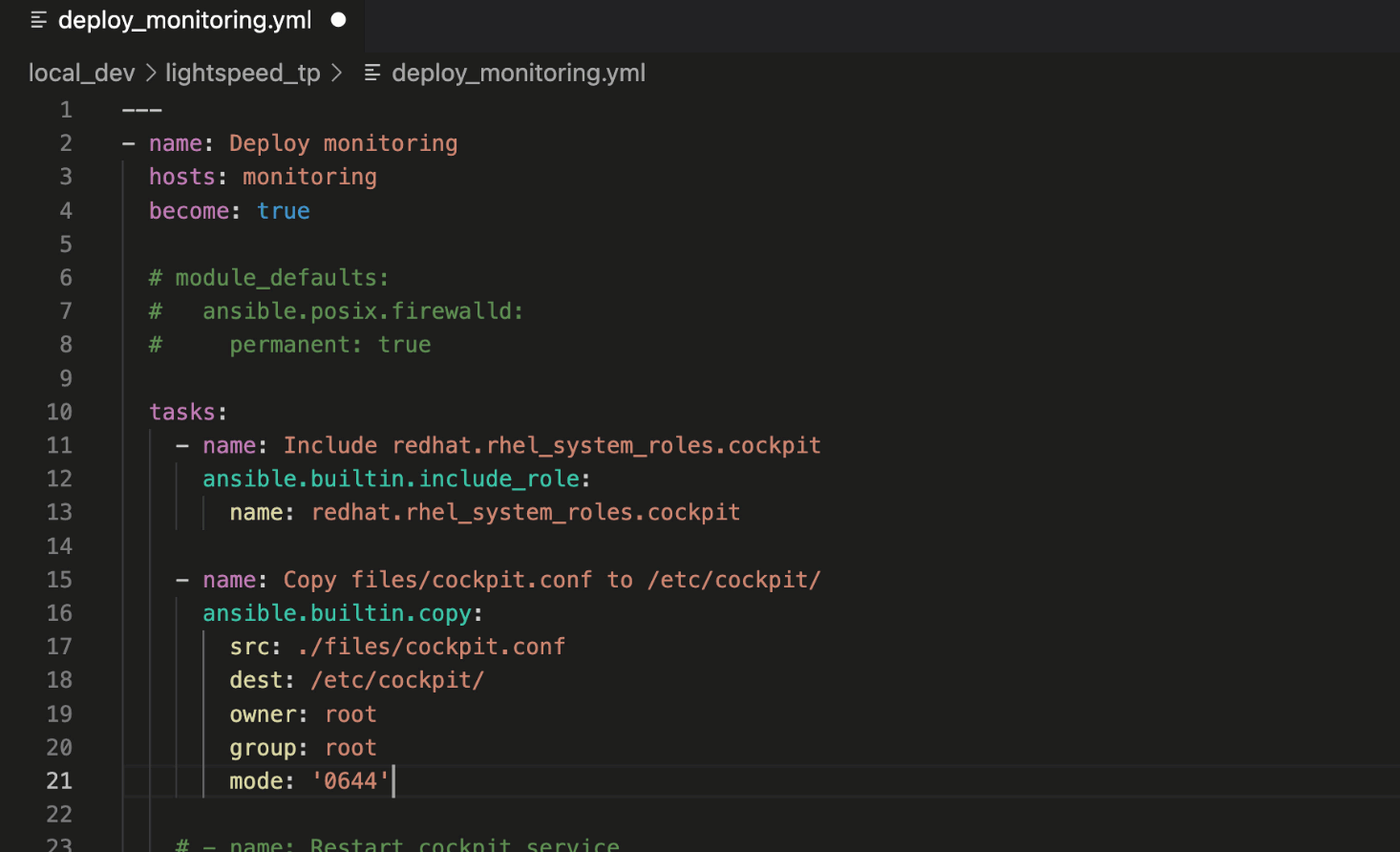
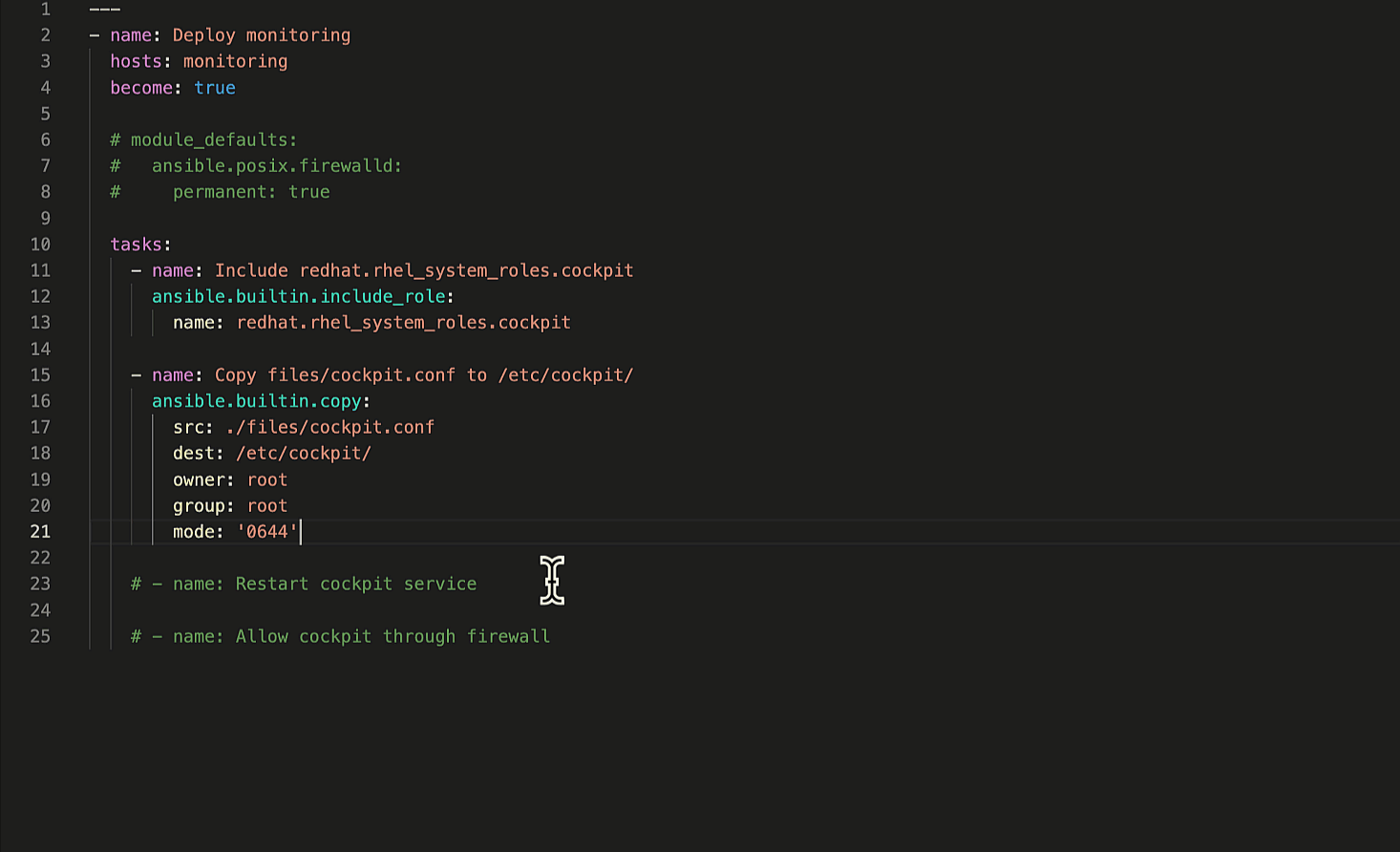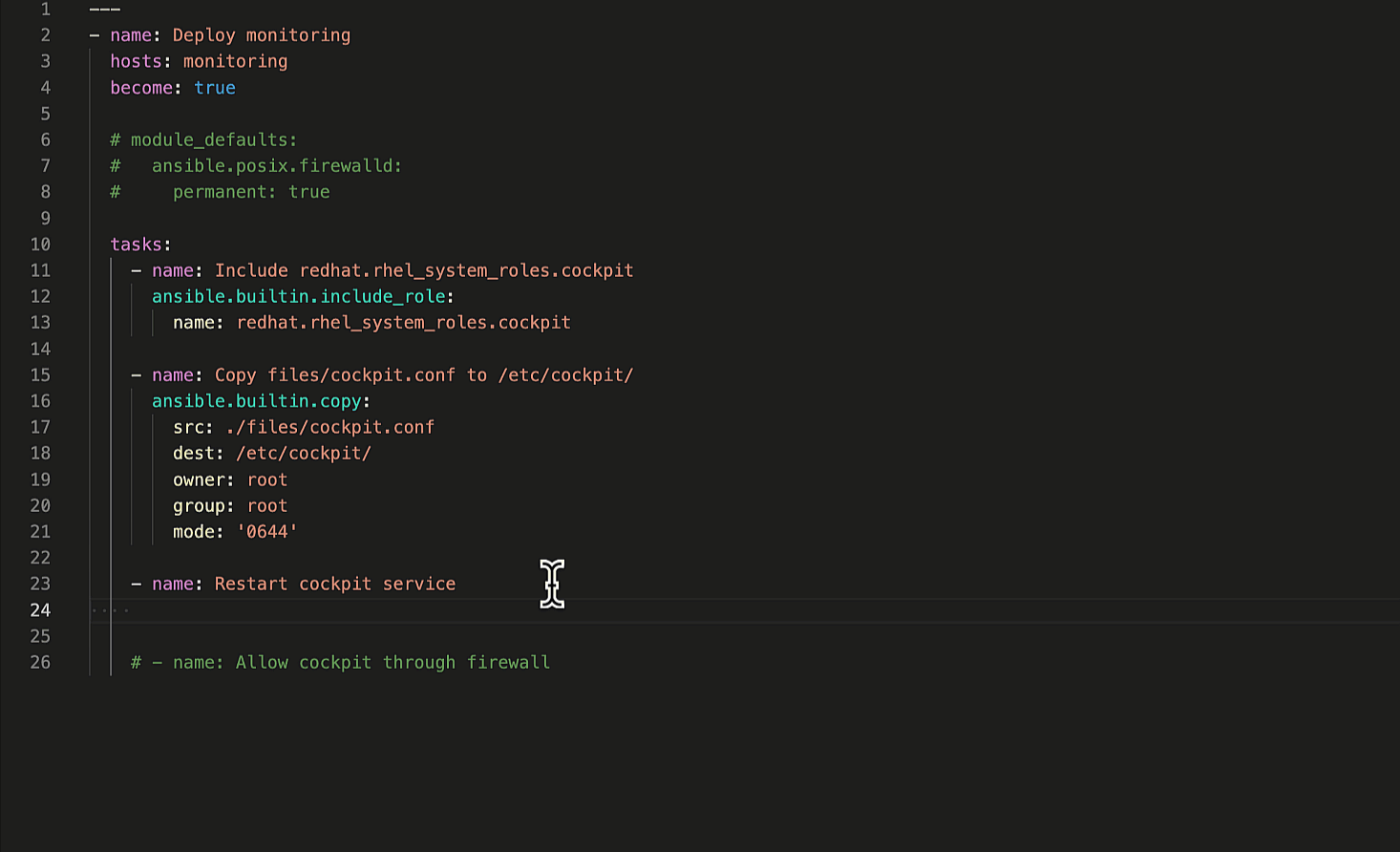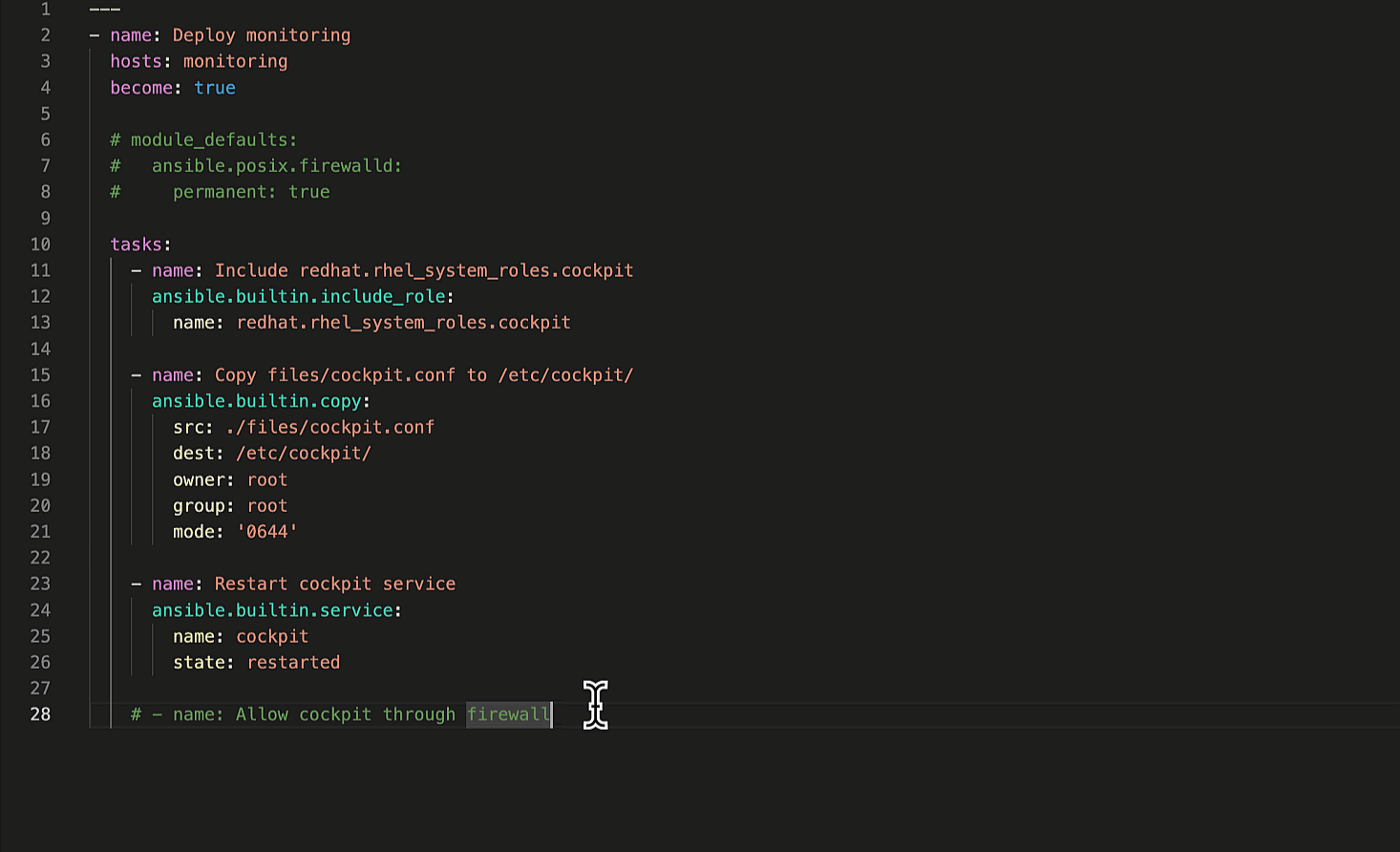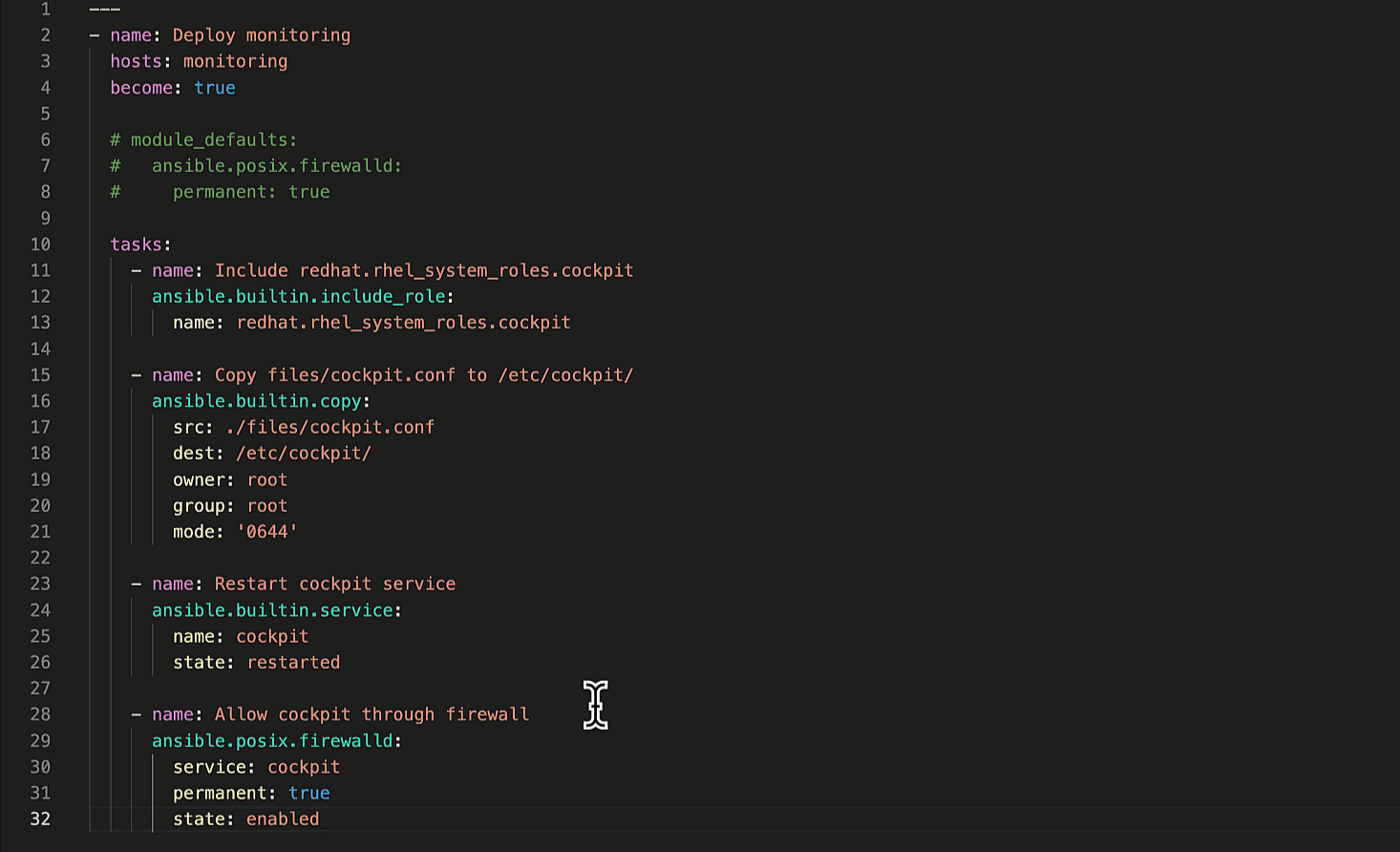
下一步是进行实际的数据操作。
深入其中
这里是我们真正想要做的事情,从源获取数据,对其进行循环,并提取所需的数据。由于数据包含在嵌套列表中,因此存在内外循环要遍历。
for workflow in data_in: workflow_data["workflows"].append(workflow["name"]) for node in workflow["related"]["workflow_nodes"]: if node["unified_job_template"]["type"] == "inventory_source": workflow_data["inventory_sources"].append( node["unified_job_template"]["name"] ) elif node["unified_job_template"]["type"] == "job_template": workflow_data["job_templates"].append( node["unified_job_template"]["name"] ) elif node["unified_job_template"]["type"] == "workflow_approval": workflow_data["approval_nodes"].append( node["unified_job_template"]["name"] ) else: raise AnsibleFilterError( "Failed to find valid node: {0}".format(workflow) )
第一个循环是找到工作流名称字段并将其追加到工作流列表中。下一个循环遍历每个工作流节点,找到它的类型,并将其追加到相应的列表中。
最后是错误消息,对于有效数据,不应出现此消息,但是当构建或调试模块时,将它插入其他地方是一个有用的代码段,以强制输出到控制台,以便找出发生了什么。在我们的操作结束时,使用结果变量返回。另一种方法是三个任务,其中两个将使用循环,以实现相同的结果。通过使用实际的编程语言、它可用的库和内嵌循环,它简化了剧本,并提供了比单独使用 YAML 和 Jinja2 可以拼凑出来的更好的逻辑。
总结
希望本文能为创建过滤器和简化剧本中的任务提供一个起点。就像 Ansible 中的一切一样,没有单一的解决方案,而是 10 个选项可供选择。并非所有解决方案都适合当前情况。希望这能提供另一个更好的选项来使用。