关于重组 Ansible 项目的想法
关于重组 Ansible 项目的想法
Ansible 能够流行起来,很大程度上是因为我们在早期就采用了几个关键原则,并且一直坚持这些原则。
第一个关键原则是简单性:易于安装、易于使用、易于查找文档和示例、易于编写剧本以及易于贡献代码。
第二个关键原则是模块化:可以通过编写模块轻松扩展 Ansible 功能,任何人都可以编写模块并将其贡献回 Ansible。
第三个关键原则是“自带电池”:所有 Ansible 模块都将内置,因此您无需弄清楚从哪里获取它们。它们就在那里。
我们通过遵循这些原则取得了长足的进步,并且我们打算继续坚持这些原则。
不过,最近我们一直在重新评估如何更好地构建 Ansible 以支持这些原则。我们现在发现自己正在处理规模问题,这些问题变得越来越难以解决。Jan-Piet Mens 从 Ansible 最初的早期就一直是 Ansible 的密友,他最近 简洁地描述了 这些问题,他从长期贡献者的角度出发,我认为他对我们面临的问题的分析非常准确。简单来说,我们成为了自身成功的受害者。
成功意味着增长,增长意味着更多用户、更多客户、更多贡献者以及更多责任——这带来了复杂性的增加。我们继续构建诸如 Ansibot 之类的工具来帮助我们管理这种复杂性,但是随着我们继续朝着超大规模发展,即使我们合并了越来越多的社区代码,我们也看到越来越多的拉取请求和问题被忽视了。
请考虑以下关于 Ansible 项目贡献演变的可视化表示

我们当前面临的大多数挑战都源于 **我们的简单模型无法处理的日益增长的复杂性**。如果我们想突破当前的限制,我们就需要构建一个新的组织模型来做到这一点。
这正是我们一直在努力的方向——这需要一些时间,因为这是一系列复杂的挑战——但我们正在取得进展。
因此,让我们讨论一些关键挑战。
首先,是 **不断增长的支持挑战**。
最初,Ansible 采用了简单的策略:如果我们发布了它,我们就支持它。在最初,这项策略非常合理;我们拥有相对较少的模块,并且我们也拥有相对较少的客户。Ansible 支持团队非常了解所有模块,足以向任何愿意为此付费的支持人员提供所有模块的支持。
但实际上,自己支持模块可能是一个棘手的命题,而且我们发展得越大,它就变得越棘手。我们的大多数模块都是 社区维护的。我们显然非常了解 Ansible 本身,但我们并不像我们的贡献者那样了解社区维护的模块。在某些情况下,我们甚至可能无法访问模块与其交互的基础软件或硬件;在这种情况下,我们完全依赖我们的社区来保持模块的正常运行。
我们的一些社区维护人员反应异常迅速。有些反应较慢。这是社区开发软件的本质。但由于所有模块都位于同一位置,并且是我们“自带电池”模型的一部分,因此许多人(包括付费客户)都没有意识到这种区别的存在。
让我们将企业支持负担强加给志愿者贡献者是不公平的。同样重要的是,我们必须尽可能清楚地向客户说明作为其订阅的一部分完全支持的内容以及不支持的内容。
接下来,是 **生命周期挑战**。
随着 Ansible 本身变得越来越成熟并被越来越多的企业客户使用,Ansible 的生命周期正在放缓。即使在最近之前,我们每四个月就会发布一个 Ansible 的主要版本,但我们最近的发布周期是八个月,并且这种较慢的发布周期将成为常态。
这是一个挑战,因为它意味着随着时间的推移,新代码到达用户需要更长的时间。这对我们的合作伙伴来说尤其具有约束力;在当前的结构下,他们只能按照我们的时间表更新他们的模块和插件。我们已经收到许多合作伙伴的反馈,他们希望能够独立于我们的发布周期发布自己的模块和插件,并且随着我们的发布周期继续放缓,我们预计这些呼声会越来越高。
然后,是 **标准提高的挑战**。
每个人,包括合作伙伴和社区,都希望模块越来越好:编写得更好、测试得更好、更安全。在每次发布中,我们都会尝试提高质量标准。
例如,对于即将发布的 Ansible 2.9 版本,我们预计很快就会要求贡献者 为每个模块提供基本的集成测试。
标准提高带来了自身的挑战。我们如何处理以前足够好的但不再符合新标准的贡献?我们如何处理不一定能够或愿意完成达到这些标准所需工作的贡献者?对于那些没有跟上我们不断提高的质量标准的现有模块,我们该怎么办——我们是否以某种方式标记它们,或者我们是否完全将它们从 Ansible 中剔除,即使它们是许多人依赖的相对稳定的模块?我们继续努力解决这些问题。
这将我们引向了 **新的模块贡献者挑战**。
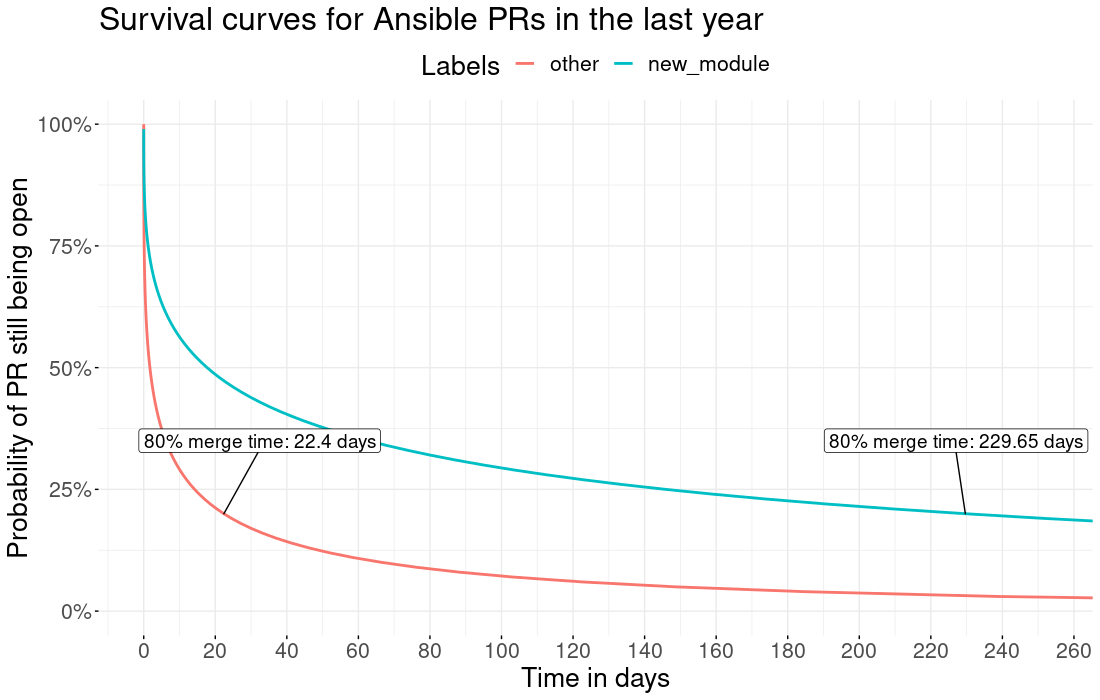
PR 的平均合并时间。新模块(蓝色)与其他所有内容(红色)。请注意,在过去的一年中,平均 80% 的非新模块 PR 在 22.4 天内合并。
随着质量标准的提高,我们吸纳新贡献者的能力下降了——或者至少放缓了。与过去相比,贡献者现在需要花费更多的时间和精力才能使他们的新模块被接受。
将 PR 引入现有模块相对容易,因为这些模块通常有获得我们集体信任的维护者。我们对现有模块的 PR 合并数量实际上非常好(当然,我们总能改进)。
但是新模块需要更高程度的审查,因为我们不仅在审查代码,而且还在暗中审查该代码的贡献者对其兴趣和维护该代码的能力。
鉴于我们目前的结构,这是一个不幸但必要的障碍。我们的支持挑战使我们更不愿意合并新模块,除非有充分的保证表明维护者愿意并且能够根据越来越严格的要求维护这些模块。
所有这些挑战的核心是,我们有一个代码库,它支持两类具有不同主要利益的参与者。
企业用户和合作伙伴最需要的是一个稳定且得到良好支持的平台,他们可以信赖该平台来自动化其 IT 基础设施。
但是我们的社区用户和贡献者需要其他东西,而这正是 Ansible 在过去一直提供的:一种简单的方法来安装 Ansible,以及简单的方法来为 Ansible 做贡献。
对于那些经历过 Red Hat 老时光的人来说,这些问题与我们在原始 Red Hat Linux 产品中遇到的问题惊人地相似——这些问题导致了 Fedora 项目和 Red Hat Enterprise Linux 的创建。我们的问题并不完全相同,但相似。
这就是为什么我们认为解决方案不应相同,但应相似。
因此,让我们谈谈 **我们解决一些这些挑战的提案**。
从 **开发角度** 来说,Ansible 将 **分解成不同的组件**
-
**核心引擎**,它基本上是运行所有其他内容的平台。保持此引擎的稳定性、安全性以及经过良好测试对于每个人都至关重要。核心团队将负责维护此引擎。社区贡献政策将与当前政策相同。
-
**核心模块和插件**,即 Ansible 团队将直接支持的模块和插件。这些将是最常用的模块和插件(例如 template、copy、lineinfile 等)。社区贡献政策将与当前政策相同,但不会引入新的模块。
-
**社区模块和插件**,大多数非核心模块和插件都将位于此处。社区贡献政策将在一定程度上放宽,以帮助吸纳新的内容和新的贡献者,但我们仍将保持一定的质量标准,以帮助确保社区内容的功能性、文档性和可用性。单独的结构将使社区能够更有效地参与策展过程。
-
各种受支持的 **合作伙伴模块和插件**,这些模块和插件将被分解并由合作伙伴更直接地管理。社区贡献政策将由各个合作伙伴自行决定。
所有这些不同的组件都将以 **Ansible 内容集合** 的形式构建,我们在 Ansible 2.8 中首次引入了这种形式。
从 **部署角度** 来说,Ansible 将以两种基本方式之一交付
-
**自带电池方法**,这与 Ansible 当前的交付方式非常相似:捆绑核心引擎、所有核心模块和插件、所有社区模块和插件以及选定的合作伙伴模块和插件,所有这些都通过集合实现。此方法将不提供官方的 Red Hat 支持。
-
**受支持的企业方法**,这将仅包含该内容的完全受支持的子集:核心模块和插件,以及选定的合作伙伴模块和插件,所有这些都通过集合实现。这将是 Red Hat 作为 Red Hat Ansible Automation 产品的一部分提供的支持方法。客户可以自行决定安装和使用任何其他内容,但 Red Hat 支持的内容和非 Red Hat 支持的内容之间的区别将更加明确。
这两种方法都将严重依赖 Ansible Galaxy 作为事实上的交付机制,我们计划对其进行大幅改进以处理增加的流量负载。
有些人可能会注意到,这个新提议的结构与我们之前迁移到,然后又在几年前放弃的Ansible Extras结构之间存在相似之处。确实如此,两者之间存在明显的相似性,许多优点和潜在缺点也相同。我们希望并打算从之前的尝试中吸取教训,在获得优势的同时,也减轻潜在的劣势。
我们相信,这些结构上的变化将有助于 Ansible 保持强大的社区关注度,同时提供支持我们不断增长的合作伙伴和客户群所需的结构。我们认识到这些都是重大的变化,这就是为什么我们计划非常谨慎地朝着这个方向发展。我们希望确保在做出这些改变之前,我们能够理解这些改变的影响。这些变化都不是迫在眉睫的,但我们认为我们已经到了可以讨论这些可能性的时候了。
还有许多问题有待解答:基础设施问题、许可问题、发布策略问题等等。我们将在即将举行的网络研讨会上讨论其中的一些问题。
我们还将在 9 月份在亚特兰大举行的 AnsibleFest 社区贡献者大会上深入探讨这些问题。我们希望在那里亲自见到我们的贡献者,但我们一如既往地努力实现完全远程参与。请以任何方式加入我们。
在 Ansible 的早期,我们只能梦想这种成功。在成立的七年时间里,我们已经建立了全球顶级的开源项目之一,并且拥有一个从一开始就推动和支持我们的忠诚社区。如果我们当时预想到今天面临的挑战,我们肯定会将它们归类为“值得拥有的好问题”。
但是,“好问题”仍然是问题,如果我们未能解决它们,它们很快就会不再是“好问题”。现在是我们迈出下一步的时候了,这样我们才能继续成为所有用户、客户和贡献者的可靠合作伙伴。没有你们所有人,我们永远不可能走得这么远。