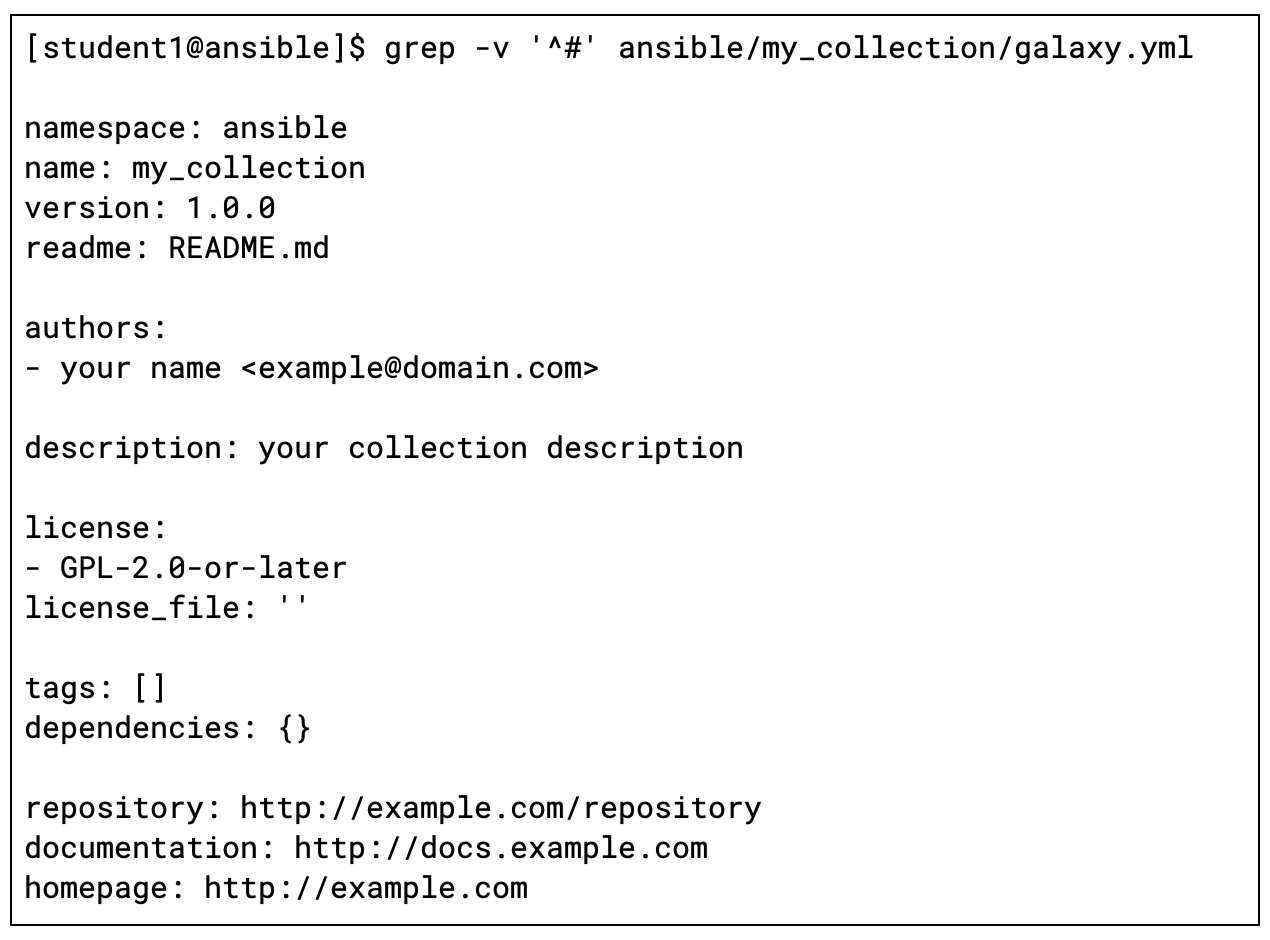
使用 Ansible 深入研究 Kubernetes 运算符,第 2 部分
在本系列的第 1 部分中,我们介绍了运算符的整体概念,以及它们在 OpenShift/Kubernetes 中的作用。我们简要了解了运算符 SDK,以及为什么您可能希望使用 Ansible 运算符,而不是 SDK 提供的其他类型的运算符。我们还探讨了 Ansible 运算符的结构,以及在使用 Ansible 构建 Kubernetes 运算符时,运算符 SDK 创建的相关文件。
在本深入研究系列的第二部分中,我们将
- 看一下创建 OpenShift 项目和部署 Galera 运算符。
- 接下来,我们将检查 MySQL 集群,然后设置和测试 Galera 集群。
- 然后我们将测试缩减规模、灾难恢复,并演示清理工作。
创建项目并部署运算符
我们首先在 OpenShift 中创建一个新项目,我们将其简单地命名为 test
$ oc new-project test --display-name="Testing Ansible Operator"
Now using project "test" on server "https://ec2-xx-yy-zz-1.us-east-2.compute.amazonaws.com:8443"
我们不会深入研究这个角色,但是基本操作是
- 使用
set_fact 使用 k8s 查找插件或 defaults/main.yml 中定义的其他变量来生成变量。
- 根据以上变量确定是否需要采取任何纠正措施。例如,一个变量确定当前运行了多少个 Galera 节点 pod。将其与
CustomResource 中定义的变量进行比较。如果它们不同,该角色将根据需要添加或删除 pod。
要开始部署,我们有一个简单的脚本,它构建运算符镜像并将其推送到 test 项目的 OpenShift 仓库中
$ cat ./create_operator.sh
#!/bin/bash
docker build -t docker-registry-default.router.default.svc.cluster.local/test/galera-ansible-operator:latest .
docker push docker-registry-default.router.default.svc.cluster.local/test/galera-ansible-operator:latest
kubectl create -f deploy/operator.yaml
kubectl create -f deploy/cr.yaml
在我们运行此脚本之前,我们需要先部署 RBAC 规则和 Galera 示例的自定义资源定义
$ oc create -f deploy/rbac.yaml
clusterrole "galera-ansible-operator" created
clusterrolebinding "default-account-app-operator" created
$ oc create -f deploy/crd.yaml
customresourcedefinition "galeraservices.galera.database.coreos.com" created
现在,我们运行脚本(在使用登录命令允许 docker 连接到我们创建的 OpenShift 仓库后)
$ docker login -p $(oc whoami -t) -u unused docker-registry-default.router.default.svc.cluster.local
Login Succeeded
$ ./create_operator.sh
Sending build context to Docker daemon 490 kB
...
deployment.apps/galera-ansible-operator created
galeraservice "galera-example" created
很快,我们将看到 galera-ansible-operator pod 启动,随后是一个名为 galera-node-0001 的 pod 和一个 LoadBalancer 服务,该服务为我们的 Galera 集群提供入口。
$ oc get all
NAME DOCKER REPO TAGS UPDATED
is/galera-ansible-operator docker-registry-default.router...:5000/test/galera-ansible-operator latest 3 hours ago
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/galera-ansible-operator 1 1 1 1 4m
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/galera-external-loadbalancer 172.30.251.195 172.29.17.210,172.29.17.210 33066:30072/TCP 1m
svc/glusterfs-dynamic-galera-node-0001-mysql-data 172.30.49.250 <none> 1/TCP 1m
NAME DESIRED CURRENT READY AGE
rs/galera-ansible-operator-bc6cd548 1 1 1 4m
NAME READY STATUS RESTARTS AGE
po/galera-ansible-operator-bc6cd548-46b2r 1/1 Running 5 4m
po/galera-node-0001 1/1 Running 0 1m
验证 MySQL 集群,初始设置和测试
我们可以使用 describe 函数查看自定义资源的状态,特别是我们指定的规模
$ kubectl describe -f deploy/cr.yaml |grep -i size
Galera _ Cluster _ Size: 1
现在我们有了 MySQL 集群,让我们使用 sysbench 对其进行测试。如上所述,我们有一个系统可以进行测试,因此我们可以避免互联网往返。但首先,我们需要一些信息。我们需要知道我们可以通过作为运算符部署的一部分创建的负载均衡服务连接到的转发端口
接下来,我们需要知道主机的 IP 地址。我们可以使用 oc describe 获取它
$ oc describe node ec2-xx-yy-zz-1.us-east-2.compute.amazonaws.com| grep ^Addresses
Addresses: 10.0.0.46,ec2-xx-yy-zz-1.us-east-2.compute.amazonaws.com
因此,对于此测试,我们将连接到 IP 地址 10.0.0.46 上的端口 XXXXX。端口值 33066 在上面的规范中指定,它将接收转发流量。我们将导出它们,以便更轻松地重复使用我们的测试命令。
从测试服务器
$ export MYSQL_IP=10.0.0.46
$ export MYSQL_PORT=XXXXX
在运行 sysbench 之前,我们需要创建它期望的数据库(将来版本的 Galera 运算符将能够自动执行此操作)
$ mysql -h $MYSQL_IP --port=$MYSQL_PORT -u root -e 'create database sbtest;'
接下来,我们将通过使用包含 100 万行的 OLTP 只读测试运行 sysbench 来准备测试
$ sysbench --db-driver=mysql --threads=150 --mysql-host=${MYSQL_IP} --mysql-port=${MYSQL_PORT} --mysql-user=root --mysql-password= --mysql-ignore-errors=all --table-size=1000000 /usr/share/sysbench/oltp_read_only.lua prepare
sysbench 1.0.9 (using system LuaJIT 2.0.4)
Initializing worker threads...
Creating table 'sbtest1'...
Inserting 1000000 records into 'sbtest1'
Creating a secondary index on 'sbtest1'
...
请注意,我们在此处使用 150 个线程,因为单个 MySQL/MariaDB 实例将其最大连接数默认设置为该值。
所以现在一切都准备就绪,让我们使用 sysbench 运行我们的第一个测试
$ sysbench --db-driver=mysql --threads=150 --mysql-host=${MYSQL_IP} --mysql-port=${MYSQL_PORT} --mysql-user=root --mysql-password= --mysql-ignore-errors=all /usr/share/sysbench/oltp_read_only.lua run
sysbench 1.0.9 (using system LuaJIT 2.0.4)
Running the test with following options:
Number of threads: 150
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 174776
write: 0
other: 24968
total: 199744
transactions: 12484 (1239.55 per sec.)
queries: 199744 (19832.77 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 10.0700s
total number of events: 12484
Latency (ms):
min: 3.82
avg: 120.66
max: 1028.51
95th percentile: 292.60
sum: 1506263.71
Threads fairness:
events (avg/stddev): 83.2267/42.84
execution time (avg/stddev): 10.0418/0.02
这只是一次运行,但重新运行几次会产生类似的结果。因此,我们的单节点集群每秒可以处理约 20K 个查询。但是只有单个成员的集群不是很有用 - 因此让我们将其扩展。我们通过编辑之前定义的自定义资源并更改 galera_cluster_size 变量来实现这一点。现在,我们将扩展到一个三节点集群
$ oc edit -f deploy/cr.yaml
galeraservice.galera.database.coreos.com/galera-example edited
接下来,我们可以验证 OpenShift 是否看到了这个新值
$ kubectl describe -f deploy/cr.yaml | grep -i size
Galera _ Cluster _ Size: 3
很快,我们将看到 Ansible 运算符接收一个信号更改的事件,并开始更新集群
$ oc get pods
NAME READY STATUS RESTARTS AGE
galera-ansible-operator-bc6cd548-46b2r 1/1 Running 5 30m
galera-node-0001 1/1 Running 0 26m
galera-node-0002 0/1 Running 0 1m
galera-node-0003 0/1 Running 0 56s
在大约一分钟后(每个 Galera 节点必须启动并从另一个成员同步数据),我们将看到新的 pod 变得可用
$ oc get pods
NAME READY STATUS RESTARTS AGE
galera-ansible-operator-bc6cd548-46b2r 1/1 Running 5 31m
galera-node-0001 1/1 Running 0 27m
galera-node-0002 1/1 Running 0 2m
galera-node-0003 1/1 Running 0 2m
现在我们有了三节点集群,我们可以重新运行与之前相同的测试
$ sysbench --db-driver=mysql --threads=150 --mysql-host=${MYSQL_IP} --mysql-port=${MYSQL_PORT} --mysql-user=root --mysql-password= --mysql-ignore-errors=all /usr/share/sysbench/oltp_read_only.lua run
sysbench 1.0.9 (using system LuaJIT 2.0.4)
Running the test with following options:
Number of threads: 150
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 527282
write: 0
other: 75326
total: 602608
transactions: 37663 (3756.49 per sec.)
queries: 602608 (60103.86 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 10.0247s
total number of events: 37663
Latency (ms):
min: 4.30
avg: 39.88
max: 8371.55
95th percentile: 82.96
sum: 1501845.63
Threads fairness:
events (avg/stddev): 251.0867/87.82
execution time (avg/stddev): 10.0123/0.01
结果很显著!我们的集群现在每秒可以处理 60K 个查询!我们能把它扩展到多远?好吧,如果您注意到我们启动时的节点数量,我们的 k8s 集群中有五个节点,因此让我们让我们的 Galera 集群与之匹配
$ oc edit -f deploy/cr.yaml
galeraservice.galera.database.coreos.com/galera-example edited
$ kubectl describe -f deploy/cr.yaml | grep -i size
Galera _ Cluster _ Size: 5
Ansible 运算符开始扩展 Galera 集群...
$ oc get pods
NAME READY STATUS RESTARTS AGE
galera-ansible-operator-bc6cd548-46b2r 1/1 Running 5 35m
galera-node-0001 1/1 Running 0 32m
galera-node-0002 1/1 Running 0 7m
galera-node-0003 1/1 Running 0 7m
galera-node-0004 0/1 Running 0 38s
galera-node-0005 0/1 Running 0 34s
在大约一分钟后,我们将再次看到一个包含五个 pod 的 Galera 集群,它们已准备好为查询提供服务
$ oc get pods
NAME READY STATUS RESTARTS AGE
galera-ansible-operator-bc6cd548-46b2r 1/1 Running 5 36m
galera-node-0001 1/1 Running 0 33m
galera-node-0002 1/1 Running 0 8m
galera-node-0003 1/1 Running 0 8m
galera-node-0004 1/1 Running 0 1m
galera-node-0005 1/1 Running 1 1m
奇怪的是,第五个节点出现问题,但 OpenShift 在其失败后重新尝试了它,它启动并加入了集群。太好了!
因此,让我们再次重新运行相同的测试
$ sysbench --db-driver=mysql --threads=150 --mysql-host=${MYSQL_IP} --mysql-port=${MYSQL_PORT} --mysql-user=root --mysql-password= --mysql-ignore-errors=all /usr/share/sysbench/oltp_read_only.lua run
sysbench 1.0.9 (using system LuaJIT 2.0.4)
Running the test with following options:
Number of threads: 150
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 869260
write: 0
other: 124180
total: 993440
transactions: 62090 (6196.82 per sec.)
queries: 993440 (99149.17 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 10.0183s
total number of events: 62090
Latency (ms):
min: 5.41
avg: 24.18
max: 159.70
95th percentile: 46.63
sum: 1501042.93
Threads fairness:
events (avg/stddev): 413.9333/78.17
execution time (avg/stddev): 10.0070/0.00
我们正在达到每秒 100K 个查询。到目前为止,我们的集群已随着我们扩展的节点数量线性扩展。在这一点上,我们已经耗尽了 OpenShift 集群的资源,扩展更多 Galera 节点无济于事
$ oc edit -f deploy/cr.yaml
galeraservice.galera.database.coreos.com/galera-example edited
$ kubectl describe -f deploy/cr.yaml | grep -i size
Galera _ Cluster _ Size: 9
$ oc get pods
NAME READY STATUS RESTARTS AGE
galera-ansible-operator-bc6cd548-46b2r 1/1 Running 5 44m
galera-node-0001 1/1 Running 0 41m
galera-node-0002 1/1 Running 0 16m
galera-node-0003 1/1 Running 0 16m
galera-node-0004 1/1 Running 0 9m
galera-node-0005 1/1 Running 1 9m
galera-node-0006 1/1 Running 0 1m
galera-node-0007 1/1 Running 0 1m
galera-node-0008 1/1 Running 0 1m
galera-node-0009 1/1 Running 0 1m
$ sysbench --db-driver=mysql --threads=150 --mysql-host=${MYSQL_IP} --mysql-port=${MYSQL_PORT} --mysql-user=root --mysql-password= --mysql-ignore-errors=all /usr/share/sysbench/oltp_read_only.lua run
sysbench 1.0.9 (using system LuaJIT 2.0.4)
Running the test with following options:
Number of threads: 150
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 841260
write: 0
other: 120180
total: 961440
transactions: 60090 (5995.71 per sec.)
queries: 961440 (95931.35 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 10.0208s
total number of events: 60090
Latency (ms):
min: 5.24
avg: 24.98
max: 192.46
95th percentile: 57.87
sum: 1501266.08
Threads fairness:
events (avg/stddev): 400.6000/134.04
execution time (avg/stddev): 10.0084/0.01
性能实际上下降了一点!这表明 MySQL/MariaDB 非常资源密集,因此如果您想继续扩展性能,您可能需要添加更多 OpenShift 集群资源。但在这一点上,我们的集群提供的流量是最初启动时的近 5 倍。对 MySQL/MariaDB 和 Galera 的持续调整可以扩展这一点,并使我们能够进一步提高性能。但是,这里的目标是展示如何创建 Ansible 运算符来控制非常复杂、面向数据的应用程序。
缩减集群规模
由于这些额外的节点没有帮助(除了在发生故障时提供更多冗余),让我们将集群规模缩减到五个节点
$ oc edit -f deploy/cr.yaml
galeraservice.galera.database.coreos.com/galera-example edited
$ kubectl describe -f deploy/cr.yaml | grep -i size
Galera _ Cluster _ Size: 5
过了一会儿,我们将看到运算符开始终止不再需要的 pod
$ oc get pods
NAME READY STATUS RESTARTS AGE
galera-ansible-operator-bc6cd548-46b2r 1/1 Running 5 46m
galera-node-0001 1/1 Running 0 43m
galera-node-0002 1/1 Running 0 18m
galera-node-0003 1/1 Running 0 18m
galera-node-0004 1/1 Running 0 11m
galera-node-0005 1/1 Running 1 11m
galera-node-0006 0/1 Terminating 0 3m
galera-node-0007 0/1 Terminating 0 3m
galera-node-0008 0/1 Terminating 0 3m
galera-node-0009 0/1 Terminating 0 3m
灾难恢复
现在,让我们添加一些混乱。查看我们的第一个 worker xx-yy-zz-2,我们可以看到哪些 pod 正在该节点上运行
$ oc describe node ec2-xx-yy-zz-2.us-east-2.compute.amazonaws.com
...
Non-terminated Pods: (5 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits
--------- ---- ------------ ---------- --------------- -------------
openshift-monitoring node-exporter-bqnzv 10m (0%) 20m (1%) 20Mi (0%) 40Mi (0%)
openshift-node sync-hjtmj 0 (0%) 0 (0%) 0 (0%) 0 (0%)
openshift-sdn ovs-55hw4 100m (5%) 200m (10%) 300Mi (4%) 400Mi (5%)
openshift-sdn sdn-rd7kp 100m (5%) 0 (0%) 200Mi (2%) 0 (0%)
test galera-node-0004 0 (0%) 0 (0%) 0 (0%) 0 (0%)
...
因此 galera-node-0004 正在此处运行,以及一些其他基础设施部分。让我们从 AWS EC2 控制台重新启动它,看看会发生什么...
$ oc get nodes
NAME STATUS AGE
ec2-xx-yy-zz-1.us-east-2.compute.amazonaws.com Ready 1d
ec2-xx-yy-zz-2.us-east-2.compute.amazonaws.com NotReady 1d
ec2-xx-yy-zz-3.us-east-2.compute.amazonaws.com Ready 1d
ec2-xx-yy-zz-4.us-east-2.compute.amazonaws.com Ready 1d
ec2-xx-yy-zz-5.us-east-2.compute.amazonaws.com Ready 1d
ec2-xx-yy-zz-6.us-east-2.compute.amazonaws.com Ready 1d
ec2-xx-yy-zz-7.us-east-2.compute.amazonaws.com Ready 1d
ec2-xx-yy-zz-8.us-east-2.compute.amazonaws.com Ready 1d
最终,我们将看到 galera-node-0004 进入未知状态
$ oc get pods
NAME READY STATUS RESTARTS AGE
galera-ansible-operator-bc6cd548-46b2r 1/1 Running 5 50m
galera-node-0001 1/1 Running 0 47m
galera-node-0002 1/1 Running 0 22m
galera-node-0003 1/1 Running 0 22m
galera-node-0004 1/1 Unknown 0 16m
galera-node-0005 1/1 Running 1 16m
过了一会儿,该 pod 将被终止,之后 Ansible 运算符将重新启动它
$ oc get pods
NAME READY STATUS RESTARTS AGE
galera-ansible-operator-bc6cd548-46b2r 1/1 Running 5 55m
galera-node-0001 1/1 Running 0 52m
galera-node-0002 1/1 Running 0 27m
galera-node-0003 1/1 Running 0 27m
galera-node-0004 1/1 Running 1 1m
galera-node-0005 1/1 Running 1 21m
...我们的集群又恢复到其请求的容量!
清理
由于这是一个测试,我们需要清理我们的工作。完成后,我们将使用 delete_operator.sh 脚本删除自定义资源和操作符部署。
$ ./delete_operator.sh
galeraservice.galera.database.coreos.com "galera-example" deleted
deployment.apps "galera-ansible-operator" deleted
几分钟后,所有东西都将消失。
$ oc get all
NAME DOCKER REPO TAGS UPDATED
is/galera-ansible-operator docker-registry-default.router...:5000/test/galera-ansible-operator latest 4 hours ago
总结
Galera 操作符正在开发中,绝对不适合生产环境。如果您想查看剧本本身,可以在这里查看代码。
https://github.com/water-hole/galera-ansible-operator
我们将继续开发它,目标是使其成为其他数据存储应用程序的事实标准示例。感谢您的阅读!